2 Der Lebenszyklus von Forschungsdaten
Abschnittsübersicht
-
Bearbeitungsdauer: 9 Minuten, 45 Sekunden
-
2.2 Der Forschungsdatenlebenszyklus
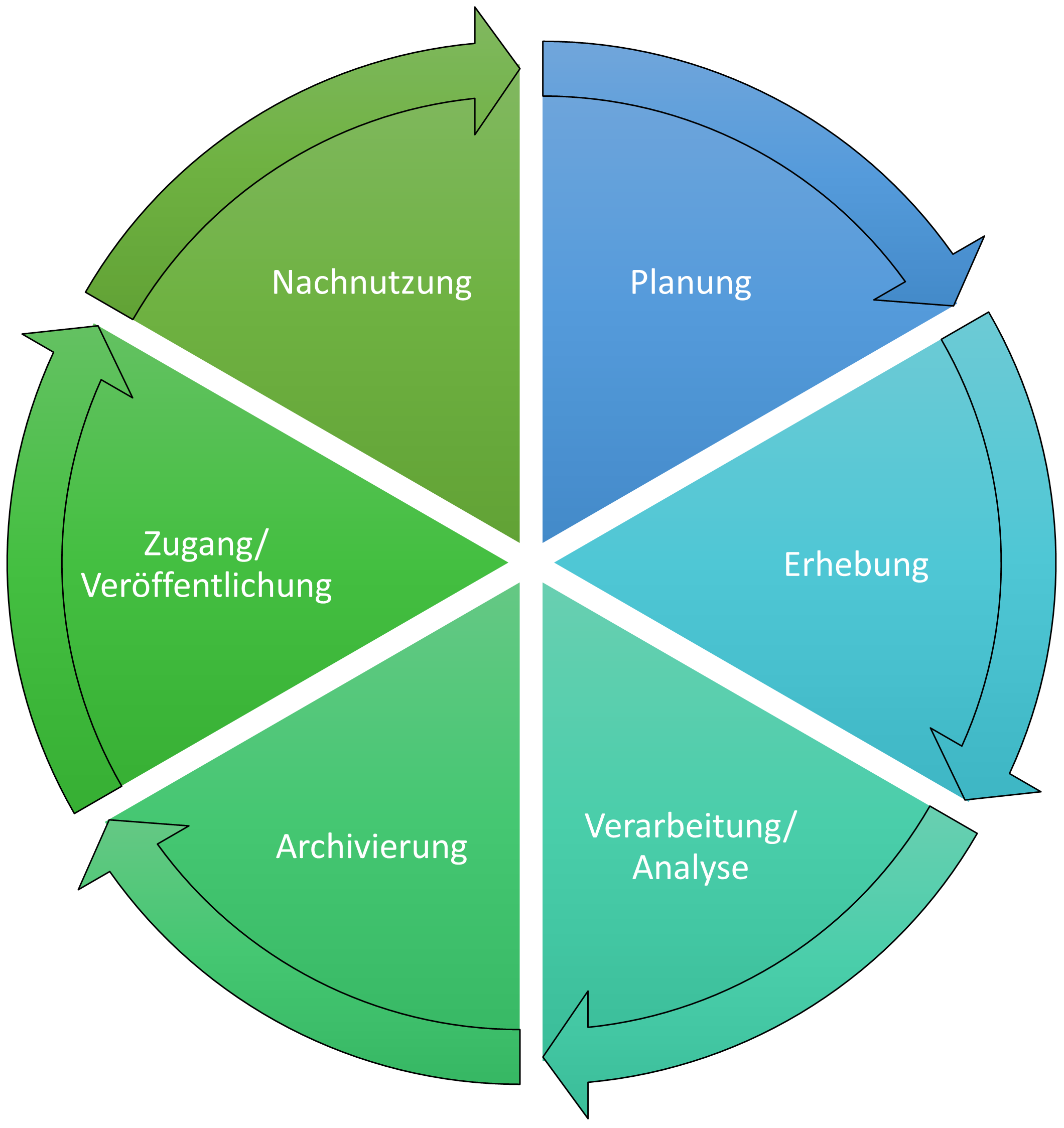
Abb. 2.1: Der Forschungsdaten Lebenszyklus (angelehnt an das DCC Curation Lifecycle Model)
Der Forschungsdatenlebenszyklus ist eine Visualisierung des Forschungsprozesses, bei der speziell die Rolle der Daten in den Blick genommen wird. Er zeigt, dass ein professioneller Umgang mit Forschungsdaten mehr beinhaltet als nur Erhebung und Analyse. Als Forscher*in lohnt es sich, in Entscheidungen immer alle Phasen mitzudenken und sich schon frühzeitig zu informieren, welche Tools und Möglichkeiten es gibt, um Ihre Praxis im Umgang mit Forschungsdaten zu optimieren.
-
2.3 Einzelne Schritte im Forschungsdatenlebenszyklus
Im Folgenden werden die einzelnen Phasen näher betrachtet und es wird beschrieben, was Sie mit Blick auf das Forschungsdatenmanagement im Einzelnen tun können.
1. Planung
“Wer scheitert zu planen, der plant zu scheitern.” - Benjamin Franklin
Nur mit guter Planung können auch gute Ergebnisse erzielt werden. Dies erfordert reifliche Überlegung, Absprachen und Recherchen. In Bezug auf das Forschungsdatenmanagement verlangen viele Forschungsförderer bereits bei der Antragsstellung einen sogenannten Datenmanagementplan (siehe Kapitel 3). Doch auch ohne explizite Vorgaben lohnt es sich, bereits im Vorfeld genau schriftlich festzuhalten, wie mit den Daten umgegangen werden soll. Das schafft Verbindlichkeit und Einheitlichkeit (insb. bei Projekten mit mehreren Beteiligten) und kann als Nachschlagewerk, Checkliste und Dokumentation dienen.
Insgesamt können für die Planung folgende Aspekte relevant sein:
- Untersuchungsdesign festlegen
- Projektteam zusammenstellen und Rollen klären
- Zeitplan aufstellen
- Datenmanagement planen (Formate, Speicherorte, Dateibenennung, kollaborative Plattformen, etc.)
- bereits existierende Literatur und Daten sichten
- ggf. Nachnutzung vorhandener Daten
- Urheberschaft und Datenbesitz klären
- Zugriffsmöglichkeiten und -bedingungen abstimmen
2. Erhebung
Die Datenerhebung kann mitunter einen erheblichen Teil der Forschungsarbeiten ausmachen. Zudem ziehen sich Fehler in dieser Phase durch den gesamten weiteren Forschungsprozess und führen im schlimmsten Fall unbemerkt zu falschen Ergebnissen. Umso wichtiger ist es, bei der Erhebung besondere Sorgfalt walten zu lassen. Neben den eigentlichen Daten betrifft dies vor allem die Dokumentation der durchgeführten Forschungsarbeiten sowie eine (möglichst standardisierte) Erfassung von Metadaten. Letzteres sind strukturierte, weiterführende Informationen über Ihre Daten, welche in Kapitel 4 näher beschrieben werden.
Insgesamt sollte die Datenerhebung folgende Aspekte umfassen:
- Durchführung der Experimente, Beobachtungen, Messungen, Simulationen etc.
- Erzeugung von digitalen Rohdaten (z. B. durch Digitalisieren oder Transkribieren)
- Speicherung der Daten in einem einheitlichen Format
- Sicherung (Backup) und Verwaltung der Daten
- Erfassung und Erstellung von Metadaten
- Dokumentation der Datenerhebung
3. Verarbeitung / Analyse
Bei der Analyse Ihrer Daten kennen Sie sich am besten aus. Hierbei ist es wichtig, dass Sie die in Ihrem Bereich üblichen Standards und Methoden anwenden und diese auch dokumentieren.
Für Sie selbst und vor allem in der Zusammenarbeit mit anderen ist es wichtig, dass Sie ein System der Dateibenennung, Versionierung und Datenorganisation haben. Als Unterstützungsleistung können Kollaborationsplattformen dienen. Weitere Informationen hierzu erhalten Sie in den Kapiteln 6 und 7.
Insgesamt können Sie bei der Datenverarbeitung und -analyse folgende Aspekte berücksichtigen:
- Daten prüfen, validieren, bereinigen (Qualitätssicherung)
- Daten ableiten, aggregieren, harmonisieren
- Fachspezifische Standards nutzen (z. B. hinsichtlich Methoden und Dateiformaten)
- Nutzung der Daten in wissenschaftlichen Publikationen vorbereiten
- Datenverarbeitung dokumentieren (zum späteren Verständnis)
- Kooperationsplattformen zum Datenaustausch mit (Fach-)Kolleg*innen nutzen
- Analysen durchführen
- Daten interpretieren
4. Archivierung
Im Kodex zur "Sicherung guter wissenschaftlicher Praxis" (2019) der Deutschen Forschungsgemeinschaft beschreibt Leitlinie 17, dass "[Rohdaten] in der Regel für einen Zeitraum von zehn Jahren zugänglich und nachvollziehbar in der Einrichtung, wo sie entstanden sind, oder in standortübergreifenden Repositorien aufbewahrt" werden sollen. Dies dient der wissenschaftlichen Qualitätssicherung und ermöglicht die langfristige Überprüfbarkeit wissenschaftlicher Erkenntnisse. Zudem können die Daten ggf. von anderen Wissenschaftler*innen nachgenutzt werden.
Um eine tatsächliche Nachnutzung zu ermöglichen, müssen jedoch einige Voraussetzungen erfüllt sein:
- Verständlichkeit
- langlebige, am besten nicht-proprietäre (d. h. kostenlos und Open Source) Dateiformate
- langlebige Speichermedien
- Auffindbarkeit
Es bietet sich daher an, auf professionelle Archivierungsdienste zurückzugreifen. Was Sie in Bezug auf die Archivierung Ihrer Forschungsdaten noch beachten sollten, lernen Sie in Kapitel 8.
5. Zugang / Veröffentlichung
Neben der (Text-)Publikation in wissenschaftlichen Zeitschriften werden auch die Daten, auf denen sie basieren, immer gefragter. Viele Forschungsförderer und Journals verlangen mittlerweile sogar eine explizite Datenpublikation. Dadurch kann zusätzlich eine Qualitätssicherung stattfinden und, wenn andere Forschende mit Ihren Daten arbeiten, erhalten Sie durch Zitationen einen Reputationsgewinn.
Grundsätzlich gibt es drei Arten der Veröffentlichung von Forschungsdaten (Biernacka et al., 2018):
- Als Beigabe zu einem wissenschaftlichen Fachartikel (= data supplement)
- Als eigenständige Veröffentlichung in einem Repositorium (= langfristiger Speicherort für Daten)
- Als Artikel in einem Data Journal:
Dies sind (in der Regel) peer-reviewte Paper, die Datensätze mit hohem Wiederverwendungswert vorstellen und näher beschreiben. Die Daten selbst sind meist in einem Forschungsdatenrepositorium veröffentlicht.
Für die Suche nach einem geeigneten Repositorium eignet sich das Portal https://www.re3data.org/. Wichtig ist, dass das gewählte Repositorium die FAIR-Prinzipien für Forschungsdaten erfüllt (forschungsdaten.org 2018). Weitere Informationen hierzu finden Sie in Kapitel 5.
6. Nachnutzung
Bei der Weitergabe und Veröffentlichung von Forschungsdaten sollten Sie darauf achten, dass diese auch tatsächlich nachgenutzt werden können. Dies eröffnet vielfältige Möglichkeiten:
- weitere Untersuchungen mit vorhandenen Daten (Sekundärdatenanalyse)
- Überprüfung von Ergebnissen (Replikation, Qualitätssicherung)
- Verknüpfung mit anderen Daten (Record Linkage)
- Nutzung in der praxisbezogenen Lehre
Voraussetzung für die Nachnutzung ist die Vergabe einer entsprechenden Nutzungslizenz. Häufig werden dabei Creative Commons Lizenzen verwendet. Im Geiste von Open Science sollten diese möglichst offen gewählt werden.
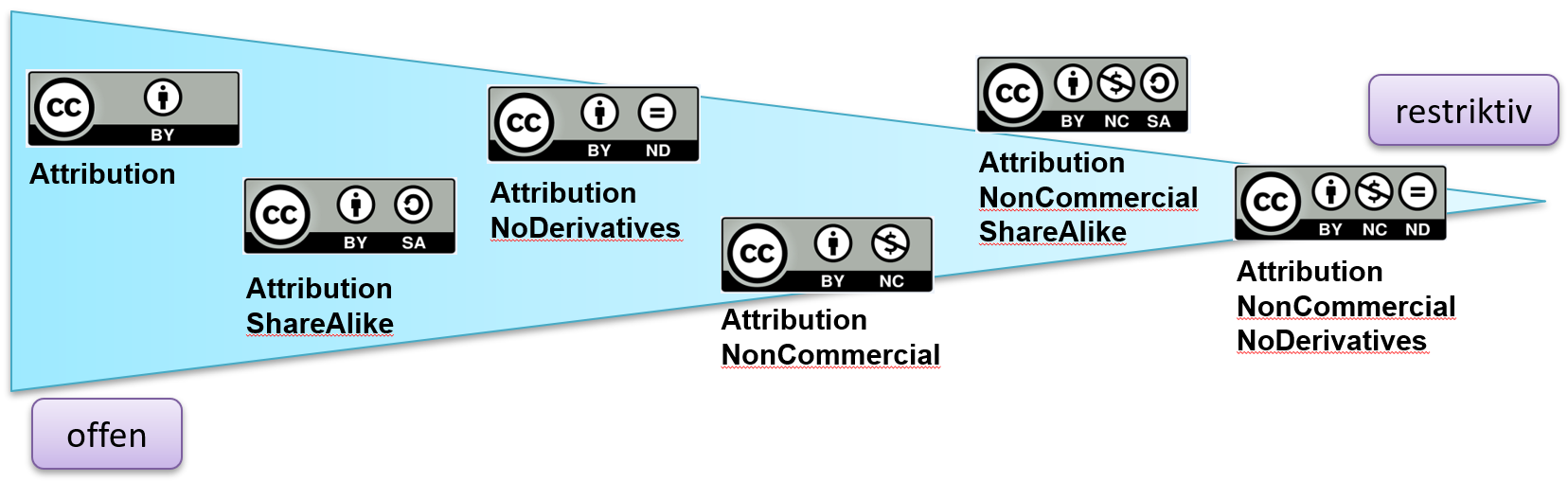
Abb. 2.2: Überblick über Creative Commons Lizenzen, Quelle: Apel et al. 2017, S. 57
Des Weiteren ist es wichtig, dass die Daten eine gute Qualität (vollständig, fehlerfrei, bereinigt, lückenlos) aufweisen und hinreichend dokumentiert sind. Zudem spielen Dateiformate eine wichtige Rolle. Diese sollten möglichst weit verbreitet und nicht-proprietär sein. Ggf. kann auch eine doppelte Ablage der Daten (einmal im Original- und einmal in einem offenen Format) sinnvoll sein. Eine Übersicht über geeignete Dateiformate finden Sie beispielsweise bei forschungsdaten.info.
Damit Daten langfristig gefunden und korrekt zitiert werden können, bietet sich die Verwendung von Persistenten Identifikatoren (PID) an. Sie verweisen dauerhaft auf einen bestimmten Inhalt (z. B. Datensatz) und eignen sich somit hervorragend für Zitationen. Ein Weblink kann sich ändern, ein PID bleibt immer gleich. Zwei Arten von PIDs können unterschieden werden:
- Identifier für digitale Objekte, z. B.
DOI = Digital Object Identifier
URN = Uniform Resource Name - Identifier für Personen (eindeutige wissenschaftliche Identität), z. B.
ORCID = Open Researcher Contributor Identification
ResearcherID
Repositorien und Journals vergeben automatisch entsprechende Identifikatoren für die dort eingereichten Daten/Beiträge. Besitzen Sie zudem einen Personenidentifier (wie bspw. ORCID), können Ihre Werke automatisch mit Ihrem Profil verknüpft werden und Sie bekommen bei jeder Nachnutzung die Zitation zugeschrieben. -
-
Hier sind noch einmal die wichtigsten Fakten zum Kapitel zusammengefasst.