4 Metadaten und Metadatenstandards
Bölüm anahatları
-
Bearbeitungsdauer: 24 Minuten, 12 Sekunden
-
4.3 Wie sehen Metadaten aus?
Metadaten liegen immer in einer bestimmten inneren Struktur vor, wenn auch die tatsächliche Umsetzung in verschiedenen Formen (z. B. von einem einfachen Textdokument über eine Tabellenform bis hin zu einer sehr stark formalisierten Form als XML-Datei, die einem bestimmten Metadatenstandard folgt) geschehen kann. Die Struktur selbst ist abhängig von den zu beschreibenden Daten (beispielsweise Nutzung von Kopfzeilen und Legenden in Excel-Tabellen im Vergleich zur formalisierten Beschreibung eines literarischen Werkes in einem OPAC), der intendierten Nutzung und den verwendeten Standards. Ganz allgemein gesagt, beschreiben Metadaten (digitale) Objekte formalisiert und strukturiert. Zu solchen digitalen Objekten gehören auch Forschungsdaten. Speziell auf unseren Anwendungsfall bezogen, kann man sagen, dass Metadaten das eigene Forschungsvorhaben und damit zusammenhängende Forschungsdaten formalisiert und strukturiert beschreiben.
Es ist sinnvoll, aber nicht zwingend notwendig, dass Metadaten nicht nur vom Menschen, sondern auch von Maschinen lesbar sind, damit Forschungsdaten maschinell und automatisiert verarbeitet werden können. Unter Maschinen sind hier vor allem Computer zu verstehen, weshalb man genauer auch von einer Lesbarkeit durch einen Computer sprechen kann. Um diese zu erreichen, müssen die Metadaten in einer maschinenlesbaren Auszeichnungssprache vorliegen. Häufig werden dafür forschungsspezifische Standards in der Auszeichnungssprache XML (Extensible Markup Language) verwendet, es gibt aber auch andere wie beispielsweise JSON (JavaScript Object Notation). Bei der Einreichung von (Forschungsdaten-)Publikationen gibt es in den meisten Fällen die Möglichkeit, die Metadaten direkt in ein vorgefertigtes Online-Formular einzutragen. Eine genaue Kenntnis von XML, JSON oder anderen Auszeichnungssprachen ist bei der Erstellung von Metadaten zum eigenen Projekt also nicht zwangsläufig erforderlich, kann aber zum Verständnis, wie die Forschungsdaten verarbeitet werden, beitragen.
Die Lesbarkeit durch Computer ist ein wesentlicher Punkt und wird beispielsweise dann wichtig, wenn verwandte Forschungsdaten durch Schlagwortsuche gefunden oder miteinander verglichen werden sollen. Eine maschinenlesbare Datei kann mithilfe von speziellen Programmen erstellt werden. Im Abschnitt "Wie erstelle ich meine Metadaten" bekommen Sie entsprechende Programme vorgestellt.
Besteht keine Kenntnis in der Erstellung von maschinenlesbaren Metadaten-Dateien, sollten Sie die Metadaten zu Ihren Forschungsdaten in einer für Sie möglichen Form abspeichern. Hierfür kann beispielsweise auch eine einfache Text-Datei über den integrierten Editor ihres Betriebssystems erstellt werden, in der jede Zeile eine Information enthält. Überlegen Sie dabei, welche Informationen für die Nachvollziehbarkeit wichtig sind (z. B. Ersteller*in der Daten, Datum der Erstellung/des Versuchs, Aufbau einzelner Versuchsanordnungen usw.). Welche Kategorien beschrieben werden müssen, hängt meist stark von Art, Umfang und Struktur der Forschungsdaten ab. Eine Übertragung in eine maschinenlesbare Form ist bei ordentlicher und nachvollziehbarer Dokumentation am Ende eines Projekts bzw. eines Teilabschnitts des Projekts immer noch möglich.
Beispiele für Metadaten
Im Folgenden soll anhand einiger Beispiele gezeigt werden, wie Metadaten aussehen können.
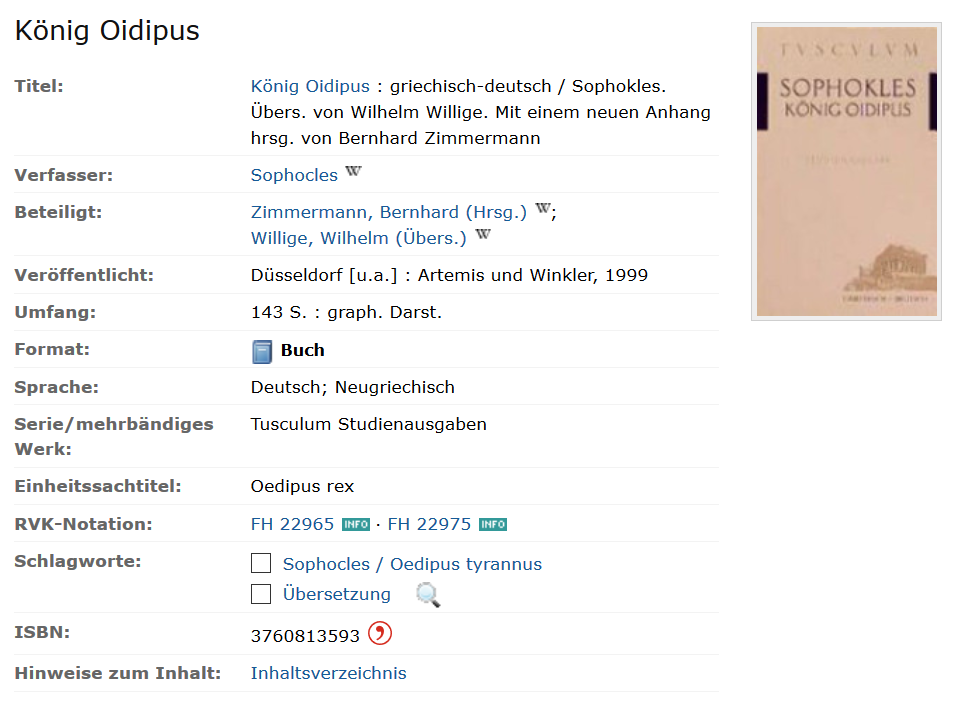
Abb. 4.1: Eintrag eines Werks in einem Online-Bibliothekskatalog, Quelle: https://hds.hebis.de/ubgi/Record/HEB060886269Abbildung 4.1 zeigt einen Buchtitel als Eintrag in einem Online-Bibliothekskatalog in einer Form, wie Sie als Angehörige einer Hochschule dies vermutlich schon des Öfteren gesehen haben. An dieser Stelle sei angemerkt, dass Metadaten keine neuartige Entwicklung darstellen und nicht erst im digitalen Zeitalter eine tragende Rolle spielen, sondern schon vorher beispielsweise beim Anlegen von Zettelkatalogen in Bibliotheken verwendet wurden, um Bücher wiederzufinden. Die in Abbildung 4.1 untereinander aufgelisteten Informationen stellen ebenfalls nichts Anderes als Metadaten dar, die aufbereitet von einem Verarbeitungssystem auch von Nutzern gelesen werden können, um Informationen über ein bestimmtes Werk zu bekommen. Sie erfahren etwas über den Titel, den*die Verfasser*in*nen, den Umfang, Angaben zum Veröffentlichungsjahr, der Sprache usw.
Auch wenn sich die Daten aus dem obigen Beispiel wahrscheinlich in hohem Maße von Ihren Forschungsdaten unterscheiden, lässt sich die Art, wie Metadaten erfasst werden, daran gut erläutern. Würde man Metadaten für Forschungsdaten in dieser Art und Weise verfassen, wie sie hier für den Nutzer erscheint, nämlich in einer Art zweispaltigen Tabelle, wobei eine Spalte die Kategorie (z. B. Titel) und eine andere Spalte die tatsächliche Information (hier „König Oidipus“) enthält, wären diese Informationen für einen späteren Forschenden für das Verständnis der Daten in jedem Falle hilfreich. Es würde aber noch nicht dazu führen, dass Computersysteme diese Daten auch automatisiert verarbeiten können.
Sollten Sie also mit der Aufbereitung von computerlesbaren Metadaten überhaupt keine Erfahrung haben, lohnt es sich, wie zuvor schon erwähnt, eine derartige tabellarische Auflistung aller relevanten Daten in einer Datei (z. B. .docx, .xlsx, .txt, o. ä.) schon zu Beginn eines Forschungsvorhabens zu nutzen und durchgehend aktuell zu halten, um bei einer möglichen späteren Einreichung diese Daten schon zur Hand zu haben. Halten Sie sich dabei auch an ein sinnvolles Versionierungskonzept, um Änderungen in den Daten im Laufe der Projektlaufzeit nachvollziehbar zu machen (siehe Kapitel 8). Abb. 4.2: Maschinenlesbare Beispiel-Metadaten gemäß dem Dublin Core Metadata Element Set, Quelle: Henrike Becker, Projekt „FOKUS“Abbildung 4.2 zeigt einen Teil eines maschinenlesbaren Metadatensatzes, der gemäß den Konventionen des Dublin Core Metadata Element Set, welches 1995 von der Dublin Core Metadata Initiative erstmals veröffentlicht wurde, in der Auszeichnungssprache XML verfasst ist (mehr dazu in Abschnitt 4.4 – „Was sind Metadatenstandards?“). Woran das erkennbar ist, wird im Folgenden erläutert.Alles, was in Abbildung 4.2 in blauer Schrift verfasst ist, bezeichnet man als Elemente, alles in schwarzer Schrift ist der Inhalt dieser Elemente. Ein einfacheres Verständnis dieses Verhältnisses ergibt sich, wenn man noch einmal Abbildung 4.1 betrachtet: Die linke Spalte ist dort die Art der Information bzw. Kategorie (also bspw. „Titel“, „Verfasser“ usw.), die rechte Spalte dann die tatsächliche Information innerhalb dieser Kategorie (also beispielsweise „König Oidipus“, „Sophocles“ usw.). Das Verhältnis von Element und Inhalt des Elements verhält sich analog, wobei die Art der Information/Kategorie die Elemente (blaue Schrift in Abbildung 4.2) und die tatsächliche Information den Inhalt der Elemente (schwarze Schrift in Abbildung 4.2) darstellen.Ein grundlegender Unterschied ist jedoch der Aufbau: Elementnamen stehen immer in einer Klammerung durch Kleiner-als- und Größer-als-Zeichen (z. B. „<…>“). Außerdem gibt es für jede Kategorie jeweils ein öffnendes und ein schließendes Element. Das öffnende Element ist erkennbar an dem Kleiner-als-Zeichen „<“ und steht immer vor der tatsächlichen Information. Das schließende Element ist erkennbar an dem Schrägstrich „/“ nach dem Kleiner-als-Zeichen „<“ und steht immer hinter der tatsächlichen Information der jeweiligen Kategorie. Diese öffnenden und schließenden Elemente umschließen also praktisch immer den dazwischenliegenden Informationsgehalt, was in Abbildung 4.2 leicht erkennbar ist. Innerhalb der Kleiner-als- und Größer-als-Zeichen steht die Angabe über die Kategorie (z. B. „title“, „creator“) usw. Die schwarz geschriebene Information zwischen <dc:creator> und </dc:creator> gibt Ihnen also beispielsweise Auskunft über den Urheber des jeweiligen Dokuments bzw. der jeweiligen Daten. Im Falle von Abbildung 4.2 wäre dies „Henrike Becker“.
Abb. 4.2: Maschinenlesbare Beispiel-Metadaten gemäß dem Dublin Core Metadata Element Set, Quelle: Henrike Becker, Projekt „FOKUS“Abbildung 4.2 zeigt einen Teil eines maschinenlesbaren Metadatensatzes, der gemäß den Konventionen des Dublin Core Metadata Element Set, welches 1995 von der Dublin Core Metadata Initiative erstmals veröffentlicht wurde, in der Auszeichnungssprache XML verfasst ist (mehr dazu in Abschnitt 4.4 – „Was sind Metadatenstandards?“). Woran das erkennbar ist, wird im Folgenden erläutert.Alles, was in Abbildung 4.2 in blauer Schrift verfasst ist, bezeichnet man als Elemente, alles in schwarzer Schrift ist der Inhalt dieser Elemente. Ein einfacheres Verständnis dieses Verhältnisses ergibt sich, wenn man noch einmal Abbildung 4.1 betrachtet: Die linke Spalte ist dort die Art der Information bzw. Kategorie (also bspw. „Titel“, „Verfasser“ usw.), die rechte Spalte dann die tatsächliche Information innerhalb dieser Kategorie (also beispielsweise „König Oidipus“, „Sophocles“ usw.). Das Verhältnis von Element und Inhalt des Elements verhält sich analog, wobei die Art der Information/Kategorie die Elemente (blaue Schrift in Abbildung 4.2) und die tatsächliche Information den Inhalt der Elemente (schwarze Schrift in Abbildung 4.2) darstellen.Ein grundlegender Unterschied ist jedoch der Aufbau: Elementnamen stehen immer in einer Klammerung durch Kleiner-als- und Größer-als-Zeichen (z. B. „<…>“). Außerdem gibt es für jede Kategorie jeweils ein öffnendes und ein schließendes Element. Das öffnende Element ist erkennbar an dem Kleiner-als-Zeichen „<“ und steht immer vor der tatsächlichen Information. Das schließende Element ist erkennbar an dem Schrägstrich „/“ nach dem Kleiner-als-Zeichen „<“ und steht immer hinter der tatsächlichen Information der jeweiligen Kategorie. Diese öffnenden und schließenden Elemente umschließen also praktisch immer den dazwischenliegenden Informationsgehalt, was in Abbildung 4.2 leicht erkennbar ist. Innerhalb der Kleiner-als- und Größer-als-Zeichen steht die Angabe über die Kategorie (z. B. „title“, „creator“) usw. Die schwarz geschriebene Information zwischen <dc:creator> und </dc:creator> gibt Ihnen also beispielsweise Auskunft über den Urheber des jeweiligen Dokuments bzw. der jeweiligen Daten. Im Falle von Abbildung 4.2 wäre dies „Henrike Becker“.An dieser Stelle sollen noch kurz die anderen in Abbildung 4.2 gezeigten Elemente erklärt werden. Das <dc:title>-Element beinhaltet den Titel unter dem das Dokument oder der Forschungsdatensatz veröffentlicht wurde. Systeme, die Titel aus einer Datenbank auslesen und anzeigen, nutzen oftmals den Inhalt dieses Elements als Information. <dc:subject> kann mehrfach vorkommen und beinhaltet immer ein Thema des Inhalts in Keywords, die als Suchgrundlage dienen. Das zweite <dc:subject>-Element in Abbildung 4.2 beinhaltet eine sehr lange Angabe eines Themas (also nicht nur Keywords), die eher vermieden werden sollte, damit bessere Suchergebnisse erzielt werden können. Das Element <dc:description> gibt eine Kurzzusammenfassung des Inhalts. Handelt es sich um Textpublikationen kann dort auch das Inhaltsverzeichnis untergebracht werden. Auch bei diesem Element sind Mehrfachnennungen möglich. <dc:date> beinhaltet ein Datum, meistens das der Veröffentlichung. Das Datum sollte, wenn es möglich ist, zur besseren Durchsuchbarkeit in Notation nach DIN ISO 8601 als JJJJ-MM-TT vorliegen. Innerhalb dieses Elements können Unter-Elemente (sogenannte Kind-Elemente) untergebracht werden, die schließlich genauere Informationen zum Datum geben, etwa, ob es sich um das Erstellungsdatum, das Datum der letzten Änderung oder das Veröffentlichungsdatum handelt. Das Element <dc:identifier> ist nur einmalig und obligatorisch in einem Metadatensatz vorhanden. Der darin enthaltene persistente Identifier ist weltweit nur einmal vergeben und weist das Dokument oder den Forschungsdatensatz eindeutig aus. Nähere Informationen zu persistenten Identifiern gibt es im folgenden Abschnitt „Welche Kategorien sind wichtig?“ sowie im Abschnitt „Findable“ von Kapitel 5.
Die zwei Buchstaben mit dem Doppelpunkt „dc:“, die in den Elementen vor dem eigentlichen Elementnamen „creator“ usw. stehen, zeigen, dass es sich bei den Elementen um Elemente aus dem anfangs erwähnten Dublin Core Metadata Element Set handelt. Genauere Informationen, warum diese beiden Buchstaben davor geschrieben werden sollten bzw. oft sogar müssen, werden im Abschnitt 4.4 – „Was sind Metadatenstandards?“ genauer erläutert.
Und nun sind Sie an der Reihe. Was sind bei der dargestellten Tabelle Daten und was sind Metadaten? Zur Auflösung klicken Sie auf das Bild.
 Abb. 4.3: Daten und Metadaten einer Excel-Tabelle
Abb. 4.3: Daten und Metadaten einer Excel-TabelleWelche Kategorien sind wichtig?
Es gibt sehr viele verschiedene Kategorien, die durch Metadaten beschrieben werden können und oft auch müssen. Je nach Disziplin und Forschungsdaten können sich diese Kategorien stark unterscheiden, manche gelten aber als Standardkategorien für alle Disziplinen.
Eine Kategorie, die spätestens im Falle einer zitierfähigen Veröffentlichung in den Metadaten vorhanden sein sollte, ist der im vorigen Abschnitt erwähnte „Persistent Identifier“. Ein Identifier dient der dauerhaften und unverwechselbaren Identifizierung. Bekannt und häufig verwendet ist der DOI (Digital Object Identifier). Ein DOI wird durch offizielle Registrierungsstellen, wie beispielsweise DataCite, vergeben. Metadaten sind über einen DOI mit dem Dokument und den Forschungsdaten verknüpft. Über einen DOI werden Forschungsdaten zitierbar. Die Zitationsvorgaben müssen in den Metadaten ebenfalls eindeutig festgelegt werden, um der guten wissenschaftlichen Praxis gerecht zu werden.
Weiterhin sollte aus den Metadaten hervorgehen, wer der*die Verfasser*in der Daten ist. Bei Gruppen von Forschenden sollten alle Beteiligten genannt werden, die an der Arbeit beteiligt waren oder eventuelle Rechte an den Forschungsdaten haben. Zu Letzteren können natürlich auch Firmen gehören, die vielleicht zur Förderung der Forschung beigetragen haben. Dabei sollte auf eine vollständige und eindeutige Namensnennung geachtet werden. Falls eine ForscherID (bspw. ORCID) vorliegt, sollte diese genannt werden.
Der Forschungsgegenstand sollte so ausführlich wie nötig beschrieben werden. Hierbei kann es mit Blick auf die Auffindbarkeit der Forschungsdaten auch sinnvoll sein, bereits Schlagwörter zu nennen, die dann bei einer digitalen Datenbank-Suche hinzugezogen werden können, um bessere Treffer zu erzielen.
Außerdem werden für die Nachvollziehbarkeit der Forschungsdaten eindeutige Informationen für Parameter wie Ort, Zeit, Temperatur, soziales Setting,... und alle anderen für die Daten sinnvollen Bedingungen benötigt. Dazu gehören auch benutzte Instrumente und Geräte mit deren genauen Konfigurationen.
Wurde zur Erstellung der Forschungsdaten bestimmte Software verwendet, muss auch der Name der Software in den Metadaten genannt werden. Dazu zählt natürlich auch die Nennung der verwendeten Softwareversion, da so spätere Forschende bei sehr alten Daten eher nachvollziehen können, warum diese Daten unter Umständen nicht mehr geöffnet werden können.
Manche Anforderungen an Metadaten sind immer gleich. Dies gilt auch für die gerade aufgelisteten Kategorien, die sehr generisch sind. Für solche Fälle existieren fachunabhängige Metadatenstandards, zu denen auch das bereits eingeführte Dublin Core Element Set gehört. Weitere Anforderungen können sich zwischen verschiedenen Disziplinen sehr stark unterscheiden. Daher existieren fachspezifische Standards, die diese Anforderungen abdecken. Mehr dazu erfahren Sie im nächsten Abschnitt 4.4 – „Was sind Metadatenstandards?“.
Abbildung 4.4 stellt verschiedene Kategorien von Metadaten dar, die sich im Hinblick auf Forschungsdaten als sinnvoll erweisen können.
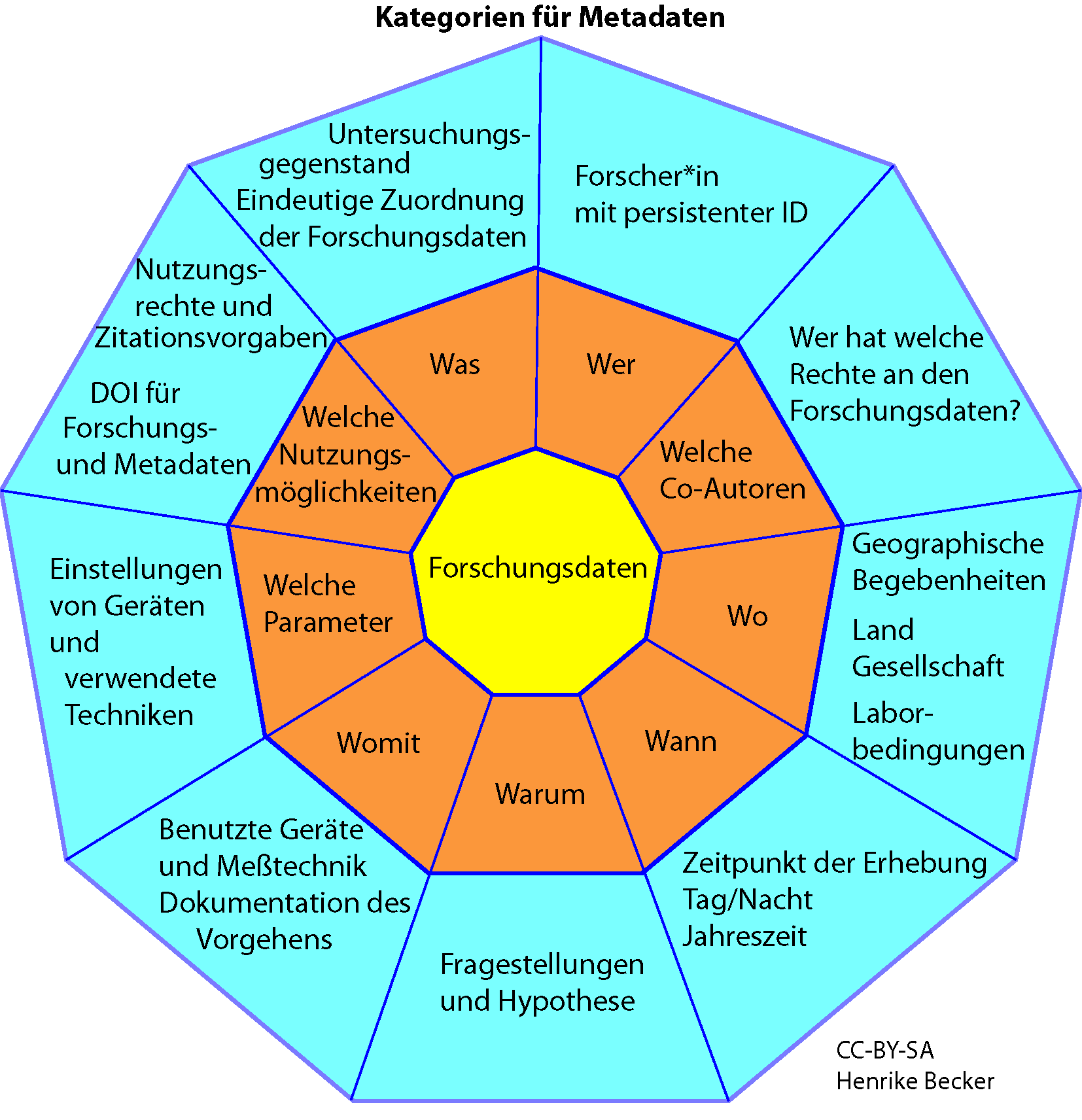
Abb. 4.4: Auflistung von Beispielkategorien, Quelle: Henrike Becker, Projekt „FOKUS“
-
-
Hier sind noch einmal die wichtigsten Fakten zum Kapitel zusammengefasst.
