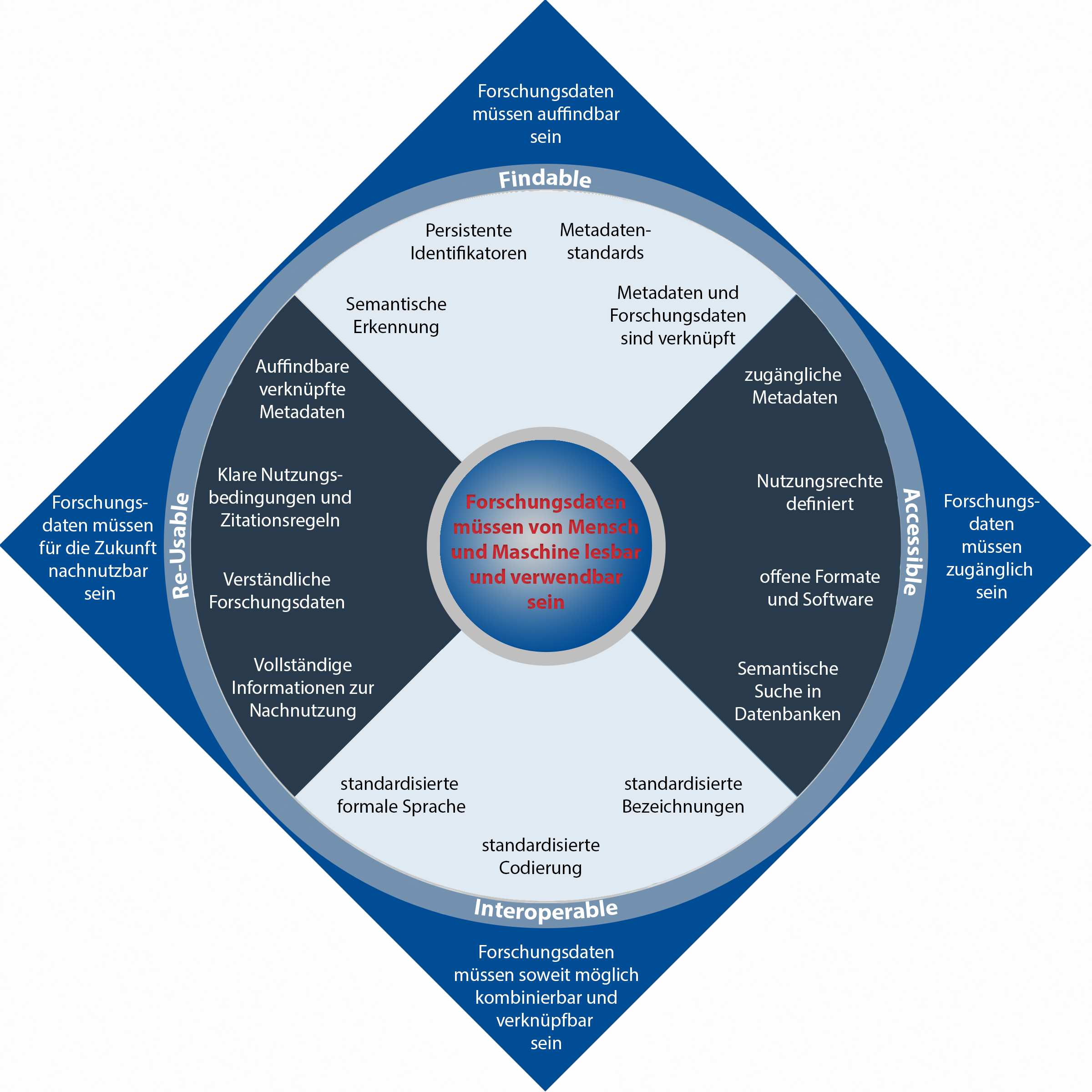
5.3 Wie bereite ich Forschungsdaten gemäß den FAIR-Prinzipien auf?
Im Folgenden sollen anhand der oben genannten Eigenschaften und auf Basis des Originaldokuments mit Bezug auf die verschiedenen Schritte im Forschungsdatenzyklus (Planung, Erhebung, Archivierung usw.) Aspekte aufgezeigt werden, um Forschungsdaten gemäß
den FAIR-Prinzipien aufzubereiten. Die vier Eigenschaften werden hier zwar getrennt voneinander betrachtet, bedürfen sich aber gegenseitig.
Die folgenden Erklärungen dienen nur als kurze Zusammenfassung zu den einzelnen Anforderungen der FAIR-Prinzipien. Einen deutlich ausführlicheren Überblick, wie Sie diese als Wissenschaftler umsetzen können, erhalten Sie beispielsweise auf den Seiten
des Weblogs der TIB.
Findability
Die Sicherstellung der Auffindbarkeit von Forschungsdaten stellt einen zentralen Punkt in der Nachnutzbarkeit dieser Daten dar. Ein wichtiger Schritt für die Möglichkeit der Wiederauffindbarkeit von Daten ist die Vergabe von sogenannten Persistent Identifiers,
die global eine eindeutige und dauerhafte Identifizierung einer digitalen Ressource sicherstellen. Eine häufig verwendete Form solcher Persistent Identifiers stellen DOI (Digital Object Identifier) dar. Dieser Identifier muss auch in den Metadaten
(siehe Kapitel 4) vorhanden sein und auf die eigentlichen Forschungsdaten verweisen, um mit diesen verknüpft zu sein. Außerdem ist es wichtig, möglichst vollständige
Metadaten und auch alle Parameter der eigentlichen Forschungsdaten zu erheben und zu dokumentieren, um die Wiederauffindbarkeit zu verbessern. Um die Daten letztendlich auffindbar zu machen, müssen die Daten am Ende noch in ein vom Menschen nutzbares
durchsuchbares System eingespeist werden.
Accessibility
Hat ein Nutzer interessante Forschungsdaten über ein Suchsystem gefunden, stellt sich ihm im Anschluss daran die Frage nach dem Zugang zu diesen Daten. Um überhaupt eine sichere Zugänglichkeit zu gewährleisten, sehen es die FAIR-Prinzipien vor, dass standardisierte
Kommunikationsprotokolle (vorwiegend http[s] und ftp) verwendet werden, die jeder Browser umsetzen kann.
Zur Veröffentlichung der Forschungsdaten gibt es die Möglichkeit, diese direkt in Forschungsdaten-Journalen oder Forschungsdatenzentren zu publizieren. Forschungsdatenpublikationen ermöglichen die Veröffentlichung aller Forschungs- und Metadaten, nicht
nur einer Auswahl an Forschungsergebnissen wie es für Peer-Review-Artikel in Fachzeitschriften bekannt und gängig ist.
Bei der Veröffentlichung von Forschungsdaten sind persistente Metadaten sehr wichtig. Um mit den FAIR-Prinzipien konform zu sein, müssen Metadaten von einmal veröffentlichten Forschungsdaten auch dann weiterhin verfügbar sein, wenn die Forschungsdaten
später möglicherweise zurückgenommen werden müssen. Diese Bedingung sollten alle Repositorien erfüllen, überprüfen Sie dies trotzdem vor der Veröffentlichung.
Es ist jedoch zu beachten, dass sich nicht alle Forschungsdaten zur freien Veröffentlichung eignen. Große Vorsicht ist geboten bei sensiblen und personenbezogenen Daten, sowie bei Rechten weiterer Personen oder einer Institution an den Forschungsdaten.
Auch wenn noch eine weitere Verwendung, beispielsweise für die Anmeldung eines Patents aussteht, müssen vor der Veröffentlichung alle Unklarheiten beseitigt werden. Falls es sich bei den Daten um sensible Daten handelt und diese deshalb nicht
frei zur Verfügung gestellt werden können, reicht es, um den FAIR-Prinzipien zu genügen, aus, an irgendeiner Stelle in den Metadaten einen Hinweis darauf zu geben, an wen man sich wenden muss, falls man Interesse an diesen Daten hat (z. B. E-Mail-Adresse,
Telefonnummer usw.). FAIR ist also nicht zwangsläufig gleichzusetzen mit Open Access, auch wenn dies erwünscht ist.
Interoperability
Der Begriff „Interoperabilität“ kommt ursprünglich aus der IT-Systementwicklung und bezeichnet die Fähigkeit von Systemen, mit anderen bereits existierenden oder auch zukünftig geplanten Systemen möglichst ohne Einschränkungen zusammenzuarbeiten. Übertragen
auf Forschungsdaten bedeutet dies einerseits, dass Daten ohne einen größeren Aufwand in andere ähnliche Daten integrierbar sein sollten und andererseits, dass die Forschungsdaten mit verschiedenen Systemen zur Analyse, Verarbeitung und Archivierung
kompatibel sind.
Um dies zu gewährleisten, wird in den FAIR-Prinzipien die Nutzung von weit verbreiteten, formalen Sprachen und Datenmodellen vorgeschlagen, die sowohl von Maschine als auch Menschen lesbar sind. Beispiele für solche Sprachen sind u. a. RDF,
OWL, aber auch fachspezifische kontrollierte Vokabulare (siehe Kapitel 4.5) und Thesauri.
Reusability
Um eine hohe Nachnutzbarkeit bzw. Wiederverwendbarkeit von Daten durch Mensch und Maschinen zu ermöglichen, müssen Forschungsdaten und die darauf bezogenen Metadaten so gut beschrieben sein, dass sie replizierbar bzw. reproduzierbar sind und im Bestfall
– wenn möglich – auch auf verschiedene Settings angewendet werden können. Dabei hilft es, soweit möglich, von Anfang an reproduzierbare Settings zu wählen und die Daten mit einer Vielzahl von eindeutigen und relevanten Attributen zu versehen, die
u. a. folgende Fragen für andere Nutzer beantworten sollten, um Rückschlüsse auf die Generierung der Daten ziehen zu können:
- Für welchen Zweck bzw. Anwendungsbereich wurden die Daten gesammelt oder generiert?
- Wann wurden die Daten erhoben?
- Basieren die Daten auf anderen eigenen oder fremden Daten?
- Wer hat die Daten unter welchen Bedingungen (z. B. Laborgeräte) erhoben?
- Welche Software und Softwareversion wurde verwendet?
- Welche Version der Daten liegt vor, falls mehrere vorliegen?
- Was waren feste Ausgangsparameter bei der Erhebung?
- Handelt es sich um Rohdaten oder bereits bearbeitete Daten?
- Sind alle verwendeten Variablen entweder irgendwo erklärt oder selbsterklärend?
Weiterhin müssen in den Daten Angaben zum Lizenzstatus gemacht, d. h. es müssen Informationen darüber vorliegen, unter welcher Datennutzungslizenz die entsprechenden Daten fallen (siehe Kapitel 9). Im Zeitalter von Open Science sind Open-Access-Lizenzen für die eigenen Daten erwünscht und bei vielen Förderern auch gefordert. Zu den bekanntesten Open-Access-Lizenzen gehören
Creative Commons und MIT, die beide auch den FAIR-Prinzipien entsprechen. Damit die Daten auch von anderen weiterverwendet werden können und ein Rückschluss auf die Herkunft genau möglich ist, sollten in den Metadaten außerdem einheitliche Informationen zur Zitation vorhanden
sein.