6 Datenqualität
Perfilado de sección
-
Bearbeitungsdauer: 13 Minuten, 47 Sekunden
Bearbeitungsdauer (ohne Video): 10 Minuten, 35 Sekunden-
6.2 Daten und Qualität – Welche Kriterien sind relevant?
Datenqualitätskriterien
Vielleicht möchten Sie eine auf Wohnort, also Postleitzahlen, basierte Untersuchung zum Diebstahlrisiko eines Autos vornehmen. Oder Sie wollen mittels eines Fragebogens herausbekommen, ob es einen Zusammenhang zwischen Studienerfolg und Abiturnoten gibt. In jedem Fall erheben Sie Daten, die Sie auswerten. Dazu müssen folgende Dimensionen der Datenqualität erfüllt ein, wobei je nach Ziel und Zweck einer Datenerhebung nicht alle Dimensionen gleichzeitig eine Rolle spielen.
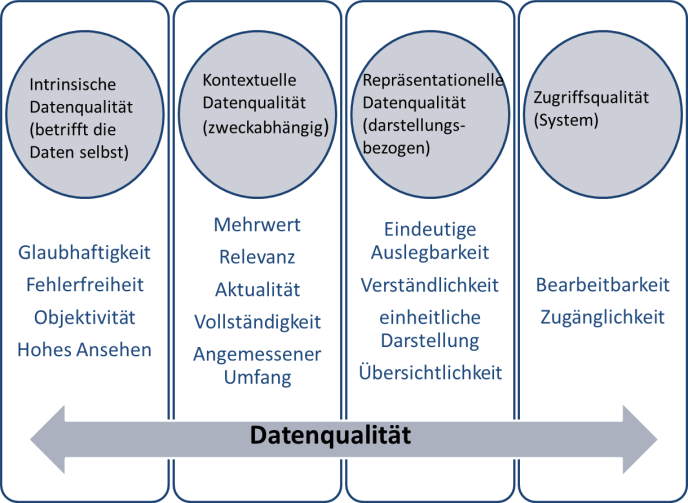
Abb. 6.1: Übersicht über Dimensionen der Datenqualität, Quelle: FOKUS
Diese Kriterien gehen zurück auf Richard Wang und Diane Strong (1996) und beschreiben Daten dann als qualitätsvoll, wenn sie von den Datennutzer*innen (dazu gehören auch Sie selbst) sowohl gegenwärtig als auch zukünftig als passend angesehen werden. Damit Forschungsdaten auch Jahre später interessant sind und nachgenutzt werden können, müssen die Daten so gründlich wie möglich beschrieben werden. Daher ist es wichtig, die Daten gut zu dokumentieren und Metadaten (siehe Kapitel 4) sowie ggf. erstellte und notwendige Forschungssoftware zum Öffnen und Betrachten der Dateien mitzuliefern.
Ein Beispiel – Datenqualitätskriterien und ihre Umsetzung
Am Beispiel der Erstellung einer Tabelle mit Unternehmensadressdaten werden die Kriterien der Datenqualität im Folgenden exemplarisch dargestellt. Mit Hilfe der Übersicht soll es möglich sein, schnelle Erkenntnisse über die Verteilung von Kunden nach Bundesländern zu gewinnen und Rechnungen gezielt an die richtigen Ansprechpersonen verschicken zu können.
Die Tabelle enthält die folgenden Merkmale:
- Interne Kundennummer
- Name des Unternehmens
- Straße
- Hausnummer
- Postleitzahl
- Ort
- Bundesland
- Nachname Ansprechpartner
- Vorname Ansprechpartner
- Telefonnummer
Das Ziel jeder wissenschaftlichen Unternehmung ist die Generierung von Wissen. In einem Prozess wird dieses aus Informationen gewonnen, die wiederum aus Daten abgeleitet werden. Damit dies geschehen kann, ist im vorliegenden Beispiel zunächst eine klare Benennung der Spalten wichtig. Erst daraus ergibt sich, dass eine bestimmte Folge von Zahlen und Symbolen (Daten) für einen bestimmten Sachverhalt (Information) steht. Selbst wenn die Zuordnung den Forschenden zum Zeitpunkt der Datenerhebung bekannt ist, sind diese Metadaten trotzdem notwendig, um die Datenerhebung auch in Zukunft verstehen zu können. Ebenso müssen natürlich auch die Daten selbst Qualitätskriterien erfüllen.
Die Kriterien im Einzelnen
Intrinsische Datenqualität:
- Glaubwürdigkeit: Hierfür müssen die Daten vertrauenswürdig und zuverlässig sein. Für unser Beispielvorhaben können Sie die Glaubhaftigkeit Ihrer Daten erhöhen, indem Sie erläutern, woher die Daten stammen.
- Fehlerfreiheit: Zur Fehlerfreiheit gehört die richtige Aufnahme der Daten. In unserem Beispiel wäre die Bezeichnung "Westfalen" falsch, denn die korrekte Bezeichnung lautet Nordrhein-Westfalen. Stammt der*die Kund*in tatsächlich aus dem Saarland, wäre auch die Bezeichnung Nordrhein-Westfalen fehlerhaft.
- Objektivität: Objektiv sind ihre Daten dann, wenn sie keine Wertungen enthalten. Im vorliegenden Beispiel würde z. B. ein Zusatz wie „schwieriger Mensch“ bei dem Vor- oder Nachnamen der Ansprechpartner das Kriterium der Objektivität verletzen.
- Hohes Ansehen: Hierbei geht es um die Reputation Ihrer Datenquelle. So können beispielsweise Daten, die Sie aus anderen Forschungsprojekten oder fachlichen Informationsportalen stammen als zuverlässiger angesehen werden als Daten von einem Datenbroker oder solche, die durch eine allgemeine Internetrecherche gesammelt wurden.
Kontextuelle Datenqualität:
- Mehrwert: Die Informationen bieten dann einen Mehrwert, wenn mit ihrer Hilfe die angestrebten Aufgaben erfüllt werden können. Im vorliegenden Beispielfall könnte das u. a. eine Abfrage zu allen Unternehmen in einem bestimmten Bundesland sein.
- Relevanz: Daten sind dann relevant, wenn sie dem Nutzer notwendige Informationen liefern. So hätten bspw. Kundendaten aus der Schweiz zwar einen Mehrwert an Informationen, jedoch keine Relevanz für die Verteilung der Unternehmen auf die deutschen Bundesländer.
- Aktualität: Ihre Daten sind dann aktuell, wenn sie einen entsprechenden Stand zeitnah abbilden. Im vorliegenden Beispiel würde eine vierstellige Postleitzahl nicht aktuell sein, da in Deutschland 1993 auf ein fünfstelliges System umgestellt wurde. Auskünfte über die Aktualität erhält man z. B. durch mitgelieferte Metadaten, Dokumentationsmaterialien oder Datumsangaben im Dokument selbst (Stand: __.__.____).
- Vollständigkeit: Ihre Daten sind dann vollständig, wenn keine Informationen fehlen. Wären in der Kundendatentabelle bspw. nur 10 der 16 Bundesländer enthalten oder gäbe es zu einigen der Kunden keine Adressdaten, bedeutete dies Einbußen in der Vollständigkeit.
- Angemessener Umfang: Die Daten liegen dann in einem angemessenen Umfang vor, wenn die gestellten Anforderungen mit der Menge an vorliegenden Daten umgesetzt werden können. In unserem Beispiel heißt das, dass für das Ziel, Rechnungen zu verschicken, Adressdaten und die Angabe, wer die zuständige Ansprechperson ist, ausreichend sind, und die Telefonnummern für diesen Fall nicht notwendig sind.
Repräsentationelle Datenqualität:
- Eindeutige Auslegbarkeit: Daten sind dann eindeutig auslegbar, wenn sie von allen, die damit arbeiten, in gleicher Art und Weise begriffen werden.
- Verständlichkeit: Ihre Daten sind dann verständlich, wenn sie von den Datennutzer*innen verstanden und für ihre Zwecke eingesetzt werden können. Für unser Ziel, eine Kundendatenbank anzulegen, bedeutet das, dass die aufgeführten Ansprechpersonen mit Vor- und Nachnamen aufgeführt werden und nicht mit Beschreibungen wie „die Frau im dritten Stock mit den braunen Haaren“.
- Einheitliche Darstellung: Wenn die Daten durchgehend auf die gleiche Art und Weise dargestellt werden, sind sie einheitlich. In unserem Fall bedeutet das, für die Angabe der Postleitzahl z. B. zu entscheiden, ob der Ziffernfolge ein „D-“ vorangestellt wird.
- Übersichtlichkeit: Die Übersichtlichkeit von Daten ist dann gewährleistet, wenn sie in einer gut erfassbaren Art und Weise dargestellt werden. In unserem Beispiel heißt das, für die verschiedenen Angaben verschiedene Spalten einzurichten, sodass die Angaben in einer inhaltlich getrennten und nicht verdichteten Form ausgegeben werden können. Gewünscht ist beispielsweise eine Adressangabe nach dem Muster:
Frau
Iris Müller
Blaue Straße 20
D-34567 Grünstadt
und nicht: FrauIrisMüllerBlaueStraße20D-34567Grünstadt
Zugriffsqualität:
- Bearbeitbarkeit: Dieses Kriterium ist erfüllt, wenn sich Ihre Daten leicht für die jeweiligen Nutzungszwecke abändern lassen. Für unsere Beispieldatenbank ist dies bspw. gegeben, wenn die Namen der zuständigen Ansprechpartner bearbeitet werden können. So können mögliche Änderungen zeitnah umgesetzt werden. Läge die Tabelle bspw. im PDF-Format vor, wäre eine Bearbeitbarkeit nicht gegeben.
- Zugänglichkeit: In unserem Beispielsfall können die betreffenden Personen direkt auf die Daten zugreifen und eine Adresse generieren, und sie müssen nicht irgendwo anrufen, um die Adressdaten genannt zu bekommen.
-
Ein Beispiel – Das Ergebnis
Und so sieht schließlich das Ergebnis aus. Bei genauerem Hinsehen erkennen Sie allerdings, dass im Ergebnis die Datenqualitätsdimensionen nicht fehlerfrei umgesetzt wurden. Finden Sie die Fehler?
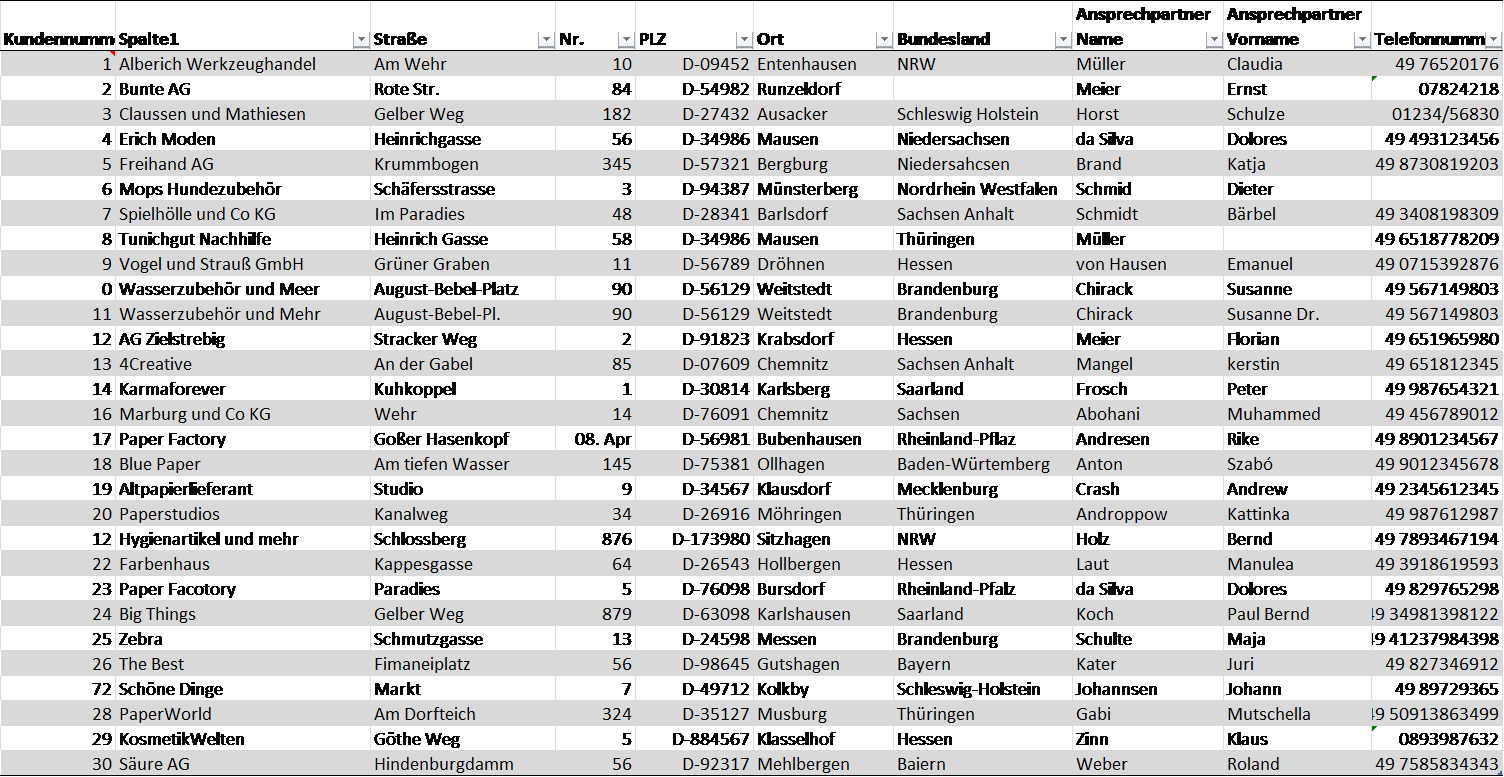
Abb. 6.2: Beispieltabelle zu Datenqualität, Quelle: FOKUS
Zur genauen Fehleranalyse betrachten Sie bitte das folgende Video:
-
-
Hier sind noch einmal die wichtigsten Fakten zum Kapitel zusammengefasst.