7 Datenorganisation
Abschnittsübersicht
-
Bearbeitungsdauer: 21 Minuten, 46 Sekunden
Bearbeitungsdauer (ohne Video): 11 Minuten, 53 Sekunden-
7.4 Verzeichnisstruktur
Eine Verzeichnisstruktur (auch Verzeichnisbaum genannt) ist die Anordnung, in der Ordner angelegt werden. Hierarchische Strukturen erleichtern dabei das Auffinden von Daten (siehe Abbildung 7.1).
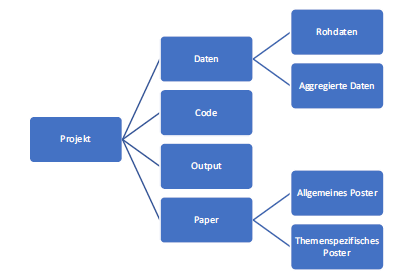
Abb. 7.1: Verzeichnisstruktur bzw. Verzeichnisbaum, Quelle: Biernacka et al. 2018, S. 51
Die Verzeichnisstruktur sollte klar ersichtlich und damit auch für andere Forschende verständlich sein. Hierfür einige Tipps:
- Verwenden Sie trennscharfe Bezeichnungen für Ihre Ordner
- Vermeiden Sie gleiche Bezeichnungen/Namen für Unterordner innerhalb eines Asts im Verzeichnisbaum
- Achten Sie auf ein ausgewogenes Verhältnis zwischen Breite und Tiefe der Struktur. Vermeiden Sie es sowohl viele, thematisch unterschiedliche Dateien in einem Ordner abzulegen, als auch unnötig viele Unterordner in einem Verzeichnis zu erstellen
- Die Voranstellung von Unterstrichen (“_”) oder Zahlen (01, 02, 03 usw.) bei der Benennung von Ordnern, kann bei der Strukturierung helfen
Zur Dokumentation aller Benennungskonventionen und Ablagestrukturen ist es zudem hilfreich, eine Text-Datei anzulegen, welche alle notwendigen Informationen enthält, um den Inhalt des Ordners nachvollziehen zu können. Diese sollte immer auf der obersten Ebene und im Format .txt gespeichert werden, um die Lesbarkeit ohne spezielles Programm zu gewährleisten.
-
7.5 Dateibenennung
Nicht nur die Speicherstruktur, sondern auch die Benennung von Daten und Dateien sollte logisch nachvollziehbar sein. Dazu bieten Ihnen die folgenden Hinweise zu Dateinamen und Schreibweisen eine Orientierung.
Dateiname:
Der Dateiname sollte objektiv und intuitiv sowie personenunabhängig nachvollziehbar sein. Die Benennung und die Kennzeichnung können nach den folgenden drei Kriterien erfolgen:
- System – wichtig für den späteren Zugriff und Abruf der Daten ist die Berücksichtigung des Systems, unter dem die Datei gespeichert wird.
- Kontext – der Dateiname beinhaltet inhaltsspezifische oder deskriptive Informationen, damit unabhängig vom Speicherort klar bleibt, zu welchem Kontext die Datei gehört, z. B. „Zeitplan.pdf“ oder „ZeitplanProjektname.pdf“.
- Konsistenz – wählen Sie die Namenskonvention vorab, um sicher zu stellen, dass sie systematisch befolgt werden kann und die gleichen Informationen (wie z. B. Datum und Zeit) in derselben Reihenfolge beinhaltet (z. B. JJJJ-MM-TT). Dateinamen sollten so lang wie nötig und so kurz wie möglich sein, um übersichtlich zu bleiben und unter jedem Betriebssystem lesbar zu sein. Für eine einheitliche Namensgebung kann man auf die folgenden Namensbestandteile zurückgreifen:
- Inhalt
- Ersteller
- Erstellungsdatum
- Bearbeitungsdatum
- Bezeichnung der Arbeitsgruppe
- Publikationsdatum
- Projektnummer
- Versionsnummer
Schreibweise:
- Sonderzeichen (wie { } [ ] < >
* % # ‘ ; “ , : ? ! & @ $ ~), Leerzeichen und Punkte sollten vermieden werden, da sie unter verschiedenen Systemen unterschiedlich interpretiert werden und dies zu Fehlern führen kann. Verzichten Sie auch auf Umlaute (ä ö ü). Bei den meisten Betriebssystemen kann man Leerzeichen mit Unterstrichen ersetzen oder den Anfangsbuchstaben von Wörtern großschreiben. Die Schreibweise mit Großbuchstaben wird in der Fachsprache auch CamelCase, in Anlehnung an die Höcker eines Kamels, genannt (siehe Abbildung 7.2). Die Schreibweise mit Unterstrichen nennt sich Snake_Case (siehe Abbildung 7.3).
- Um eine chronologische Sortierung zu ermöglichen, empfiehlt es sich, den Namen mit Datumsangabe zu beginnen, zum Beispiel JJMMTTName oder JJJJ-MM-TT_Name:
- 181123CamelCase.txt
- 2018-11-30_snake_case.txt
- Weitere Beispiele für einheitliche Namensgebung:
- 2016-05-12_Klimamessung1_original.jpg
- 2016-05-22_Klimamessung1_MHU_Ausschnitt.jpg
- 2016-05-23_Klimamessung1_MHU_Ausschnitt_bearbeitet_Farbe.jpg
- Automatisch generierte Namen (z. B. von der Digitalkamera) sollten vermieden werden, da sie zu Konflikten durch Wiederholung führen können. Lassen Sie bei der Entscheidung der Namenskonvention die Skalierbarkeit nicht außer Acht: z. B. bei der Wahl einer zweistelligen Dateinummer beschränkt man die Daten auf 00-99 Dateien.
- Nicht nur bei größeren Projekten, sondern auch bei kleineren Forschungsvorhaben, ist es lohnenswert, die gewählten Namenskonventionen schriftlich festzuhalten. Erläutern Sie insbesondere gewählte Abkürzungen in einem Datenmanagementplan oder einer Readme-Datei. Eine Rekonstruktion dieser Konventionen ist nach Jahren oft nur schwer möglich.
- Falls Sie eine ID (siehe auch Kapitel 4) oder Studiennummer haben, sollten Sie diese beifügen, um die Daten zweifelsfrei zu einer Studie und einem Forschenden zuordnen zu können (insbesondere, wenn mehrere Forschende an einem Projekt arbeiten).
- Vermerken Sie durch Kürzel, um welchen Datentyp es sich handelt; z. B. Fragebogen, Experiment, Exzerpt, Audiodatei, etc.


Abb. 7.2: Visualisierung camelCase
(Quelle: Lea Dietz)Abb. 7.3: Visualisierung snake_case
(Quelle: Lea Dietz)
Umbenennung:
Für die Umbenennung bestehender Dateinamen gibt es in Windows mehrere Alternativen. Mittels Rechtsklick und Auswahl des Kontextpunktes ist ein einfaches Umbenennen möglich. Weiterhin kann nach Markieren der jeweiligen Datei die Taste “F2” auf der Tastatur genutzt werden.
Möchten Sie mehrere Dateien gleichzeitig nach bestimmten Konventionen umbenennen, benötigen Sie dafür eine geeignete Software. Diese existiert für die meisten Betriebssysteme.
- Windows:
- Mac:
- Linux:
- GNOME Commander
- GPRename
- Unix: Unter Unix kann das Kommando “rename” hilfreich sein, um mit regulären Ausdrücken Dateien aufzufinden und umzubenennen.
In diesem Video von Christian Krippes (2018) sind die wichtigsten Grundregeln für eine strukturierte und übersichtliche Dateibenennung noch einmal kurz zusammengefasst.

-
7.7 Datenbanken und Datenbanksysteme
Geeignete Konventionen zur Benennung und Ablage von Dateien sind bereits ein wichtiger Baustein für eine effiziente Datenorganisation. Arbeiten Sie jedoch mit besonders vielen Dateien oder haben Sie besondere Anforderungen an die Strukturierung Ihrer Daten, insb. hinsichtlich der Durchsuchbarkeit, kann die Verwendung von Datenbanksystemen hilfreich sein. Hierbei werden nicht nur die Dateien selbst sinnvoll strukturiert, sondern in einer Datenbank verzeichnet und mit Metadaten (siehe Kapitel 4) versehen. Die Metadaten ermöglichen dabei gezielte Filter- und Suchfunktionen. So könnten bspw. in einer Bilddatenbank schnell und komfortabel alle Bilder angezeigt werden, die von einer bestimmten Agentur an einem bestimmten Ort zu einer bestimmten Zeit gemacht wurden. In Abbildung 7.4 werden die Grundbegriffe der Datenorganisation und ihre hierarchische Beziehung zueinander noch einmal veranschaulicht.
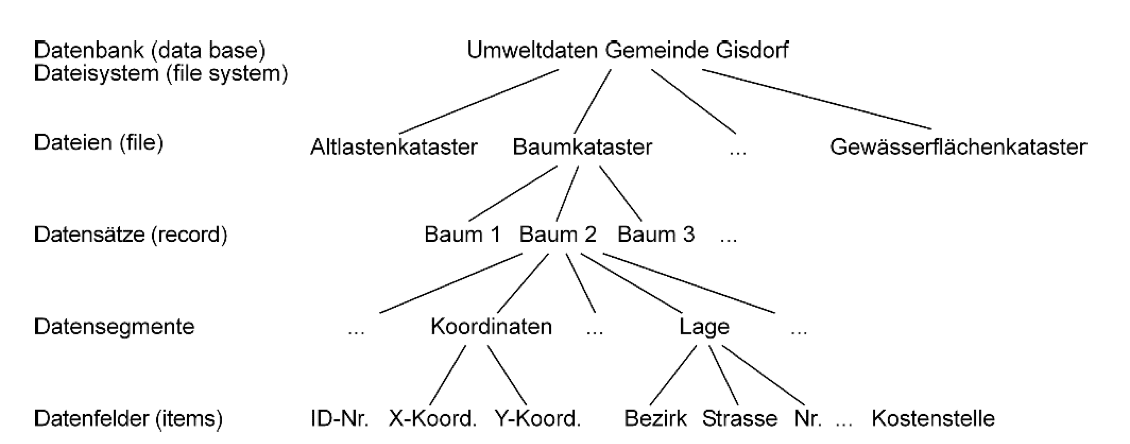
Abb. 7.4: Grundbegriffe der Datenorganisation, Quelle: De Lange 2006, S. 328
Auf der untersten Ebene der Datenorganisation befinden sich Datenfelder. Diese enthalten Attributwerte, nach denen sie logisch zusammengehörend Datensegmenten (Datengruppen) zugeordnet werden können. Mehrere Datensegmente bauen einen Datensatz auf. Logisch zusammengehörende Datensätze bilden dann eine Datei, während zusammengehörige Dateien Dateisysteme bzw. Datenbanken bilden.
Datenbanken reichen für viele Anforderungen der Nutzer allerdings nicht zur Datenorganisation aus; z. B. müssen einige Daten mehrfach an verschiedenen Orten gespeichert werden, um sie für unterschiedliche Anwendungen nutzen zu können. Zudem kann Datenschutz über die Vergabe von Zugriffsrechten nur schwer gewährleistet werden. Daher werden Datenbanksysteme benötigt.
„Ein Datenbanksystem (DBS) besteht aus dem Datenbankverwaltungssystem oder Datenbankmanagementsystem (DBMS) und mehreren Datenbanken (DB, auch Datenbasen)“ (De Lange 2006: 332). Doch was sind Datenbanken und Datenbankmanagementsysteme? Eine Datenbank besteht aus „mehreren, untereinander verknüpften Daten“ (Herrmann 2018: 5), womit sie eine Datensammlung ist, deren Daten „in einer logischen Beziehung stehen“ (Herrmann 2018: 5). Die Datenbank wird vom Datenbankmanagementsystem verwaltet; letzteres ist also eine Software.
Somit bieten Datenbanksysteme den Nutzern effizienten und gebündelten Zugang auf Daten und sollen die folgenden Anforderungen erfüllen (De Lange, 2006, S. 333):
- Auswertbarkeit der Daten nach beliebigen Merkmalen
- Einfache Abfragemöglichkeiten und Auswertung, schnelle Bereitstellung der Daten
- Zuweisung verschiedener Nutzungsrechte an die einzelnen Benutzer
- Daten und Anwenderprogramme sind unabhängig voneinander, sodass der Anwender nur die logischen Datenstrukturen kennen muss, während das DBS die organisatorische Verwaltung übernimmt
- Keine Datendopplung und Datenintegrität
- Datensicherheit bei Hardwareausfällen und Fehlern der Anwenderprogramme
- Datenschutz gegen unbefugten Zugriff
- Flexibilität hinsichtlich neuer Anforderungen
- Zulassung von Mehrbenutzerzugriffen
- Einhaltung einheitlicher Standards
Zu den geläufigsten Datenbankmanagementsystem gehören unter anderen Oracle, MySQL, Microsoft Access und SAP HANA.
-
-
Hier sind noch einmal die wichtigsten Fakten zum Kapitel zusammengefasst.