Forschungsdatenmanagement - Eine Online-Einführung
Résumé de section
-
Herausgeber: HeFDI - Hessische Forschungsdateninfrastrukturen
Kontakt: forschungsdaten@fit.fra-uas.de
Bearbeitungsdauer gesamt (ohne Videos): ca. 2,5 Stunden
Zuletzt geändert: März 2022 -
Herausgeber: HeFDI - Hessische Forschungsdateninfrastrukturen
Autor*innen (in alphabetischer Reihenfolge): Esther Krähwinkel (Philipps-Universität Marburg), Patrick Langner (Hochschule Fulda), Robert Lipp (Frankfurt University of Applied Sciences), Andre Pietsch (Justus-Liebig-Universität Gießen)
Review: Wir danken Stefanie Blum und Marion Elzner, Hochschule Geisenheim, für Ihren Input sowie den Kolleginnen und Kollegen des Thüringer Kompetenznetzwerks Forschungsdatenmanagement, der AG Prof. Goesmann, Bioinformatik und Systembiologie, Universität Gießen und Dr. Reinhard Gerhold, Universität Kassel, für ihr wertvolles Feedback.
Voraussetzungen: Für dieses Lernmodul sind keine Vorkenntnisse erforderlich. Die Kapitel sind thematisch aufeinander aufbauend, können aber auch einzeln bearbeitet werden.
Zielgruppe: Studierende, Promovierende und Forschende, die einen ersten Einstieg in das Forschungsdatenmanagement suchen.
Bearbeitungsdauer (mit Videos): 3 Stunden, 15 Minuten
Bearbeitungsdauer (ohne Videos): 2 Stunden, 10 MinutenLernziel: Nach Abschluss dieser Selbstlerneinheit können Sie die Inhalte und den Sinn von Forschungsdatenmanagement verstehen und umsetzen. Die Lernziele im Einzelnen sind den jeweiligen Kapiteln vorangestellt.
Lizensierung: Dieses Modul ist lizensiert unter Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA 4.0) und öffentlich verfügbar unter https://doi.org/10.5281/zenodo.6373595.
Datenschutz - eingebettete Videos: In diesem Lernmodul sind auf den Folgeseiten Videos von YouTube eingebettet. Beim Aufruf werden durch Google/YouTube Cookies und andere Daten verwendet, verarbeitet und ggf. weitergegeben. Informationen zu Datenschutz und Nutzungsbedingungen des Dienstes finden Sie hier. Die Nutzung des Lernmoduls setzt ein entsprechendes Einverständnis voraus.
-
- Forschungsdaten.info - Informationsportal zum Forschungsdatenmanagement im deutschsprachigen Raum
- Forschungsdaten leben länger...
- Anschauliche Lehrvideos der RWTH Aachen (Deutsch/Englisch)
- Lokale FDM-Servicestelle
der Frankfurt UAS - Hier finden Sie Ihre lokalen Ansprechpersonen,
Informationen zum Beratungs- und Schulungsangebot sowie weitere Services
- Hessische Forschungsdateninfrastrukturen (HeFDI) - Hessische Landesinitiative zur Förderung von Forschungsdatenmanagement; unter anderem durch Schulungen und Workshops
- Nationale Forschungsdateninfrastruktur (NFDI) - Bundesweite Initiative zur Erschließung und Nachnutzbarmachung wissenschaftlicher Datenbestände
- Rat für Informationsinfrastrukturen (RfII)
- Von der Gemeinsamen Wissenschaftskonferenz (GWK) berufenes
Expertengremium, das regelmäßig Berichte, Empfehlungen und
Positionspapiere veröffentlicht. Empfehlenswert ist insbesondere der
wöchentliche Mail-Service mit aktuellen Infos rund um das Thema Forschungsdatenmanagement
- Research Data Allicance Deutschland (RDA DE) - Deutschsprachiger Ableger der internationalen Community von Daten-Expert*innen
- European Open Science Cloud (EOSC) - Metaportal der Europäischen Union zur Bündelung von Services zur Verfügbarmachung von Forschungsdaten
- GO FAIR Initiative - Zentrales, europäisches Informationsportal zur Umsetzung der FAIR-Prinzipien (findable, accessible, interoperable, reusable)
- Forschungsdaten.info - Informationsportal zum Forschungsdatenmanagement im deutschsprachigen Raum
-









Quelle: Becker, Henrike, Einwächter, Sophie, Klein, Benedikt, Krähwinkel, Esther, Mehl, Sebastian, Müller, Janine, Werthmüller, Julia. (2019). Lernmodul Forschungsdatenmanagement auf einen Blick – eine Online-Einführung. Zenodo. https://doi.org/10.5281/zenodo.3381956
-
Bearbeitungsdauer: 15 Minuten, 36 Sekunden
-
1.2 Was sind Forschungsdaten und was ist Forschungsdatenmanagement?
Gemäß der „Leitlinien zum Umgang mit Forschungsdaten“, die 2015 von der DFG veröffentlicht wurden, zählen zu Forschungsdaten „u. a. Messdaten, Laborwerte, audiovisuelle Informationen, Texte, Surveydaten, Objekte aus Sammlungen oder Proben, die in der wissenschaftlichen Arbeit entstehen, entwickelt oder ausgewertet werden. Methodische Testverfahren, wie Fragebögen, Software und Simulationen können ebenfalls zentrale Ergebnisse wissenschaftlicher Forschung darstellen und sollten daher ebenfalls unter den Begriff Forschungsdaten gefasst werden.“
Der Umfang an Forschungsdaten erstreckt sich also von den typischen mit Daten agierenden Wissenschaftsdisziplinen wie den Naturwissenschaften und Sozial- sowie Wirtschaftswissenschaften über beispielsweise linguistische Sprachdaten bis hin zu Bildbeschreibungen aus den Kunstwissenschaften usw. (s. Abb. 1.1 & Abb. 1.2)
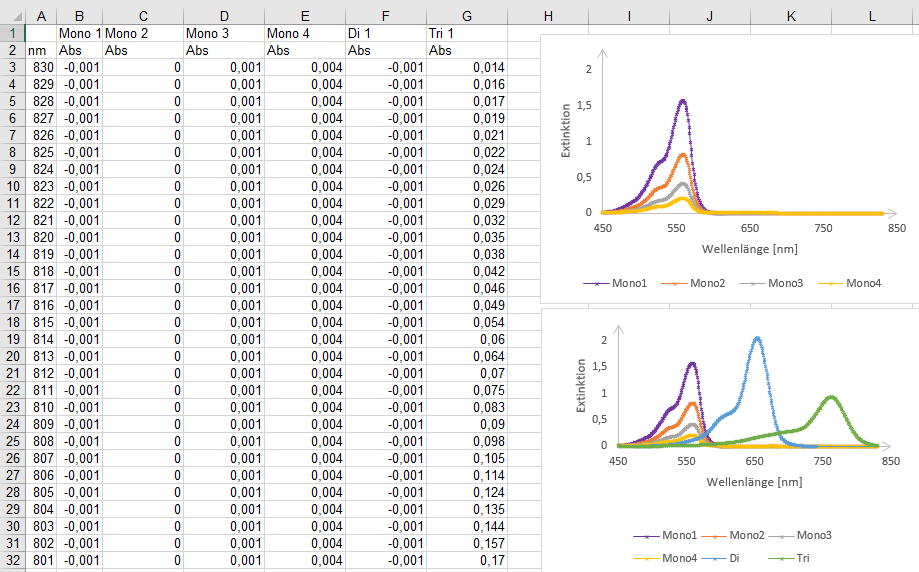 Abb. 1.1: Forschungsdaten aus der ChemieAbb. 1.2: Forschungsdaten aus den Wirtschaftswissenschaften
Abb. 1.1: Forschungsdaten aus der ChemieAbb. 1.2: Forschungsdaten aus den Wirtschaftswissenschaften
Der Kosmos an Forschungsdaten in der Wissenschaft ist auch aufgrund sich neu entwickelnder Forschungsmethoden noch nicht vollständig zu überblicken und der Umgang mit diesen birgt oft schon von Disziplin zu Disziplin unterschiedliche Herausforderungen (z. B. Umgang mit personenbezogenen Daten in sozialwissenschaftlichen Umfragen), die von den Forschenden ein strukturiertes, der guten wissenschaftlichen Praxis entsprechendes Forschungsdatenmanagement abverlangen. Der Schwerpunkt liegt dabei vor allem auf dem Umgang mit digitalen Forschungsdaten. Die besondere Herausforderung besteht dabei darin, dass aufgrund der Digitalisierung und Automatisierung von Arbeitsprozessen immer größere und heterogene Datenmengen entstehen, deren sinnvolle und koordinierte Handhabung sehr aufwändig ist. Diese Heterogenität zeichnet sich einerseits durch vielfach unterschiedlich genutzte Dateiformate (.txt, .docx, .pdf, .ods usw.) und andererseits durch unterschiedliche Darstellungsformen mit verschiedenen Abstraktionsebenen (Grafiken, 3D-Modelle, Simulationen, Umfragedaten usw.) aus.
Konventionelle wissenschaftliche Verfahren gewährleisten oft noch keine ausreichende Nutzung der großen Datenmengen. Weiterhin gibt es für den Umgang mit (digitalen) Forschungsdaten bisher nur wenige übergeordnete Standards. Die Handhabung ist vor allem durch individuelle oder fachspezifische Praktiken geprägt. Datenverlust oder die Nichtnachvollziehbarkeit von Daten sind gerade nach Projektbeendigung keine Seltenheit. Forschungsdaten können dann bspw. aufgrund fehlender Dokumentation der Arbeitsschritte oder veralteter Formate für weitere Forschungszwecke nur eingeschränkt nachgenutzt oder reproduziert werden (vgl. Büttner, Hobohm und Müller 2011: 13 ff.).
Genau an dieser Problematik setzt Forschungsdatenmanagement an und soll dem Umgang mit Forschungsdaten zukunftsfähige Chancen bieten. Forschungsdatenmanagement, kurz FDM, umfasst den gesamten Umgang mit Forschungsdaten von der Planung, der Erhebung über Verarbeitung und Qualitätssicherung bis hin zur Aufbewahrung und Zugänglichmachung bzw. Publikation. Alle Schritte des FDM sollten dokumentiert werden und sich dabei an den aktuellen fachspezifischen Standards und Gepflogenheiten der einzelnen Wissenschaftsdisziplinen orientieren. Viele wissenschaftliche Einrichtungen haben mittlerweile eine Forschungsdaten-Leitlinie veröffentlicht, die den Umgang mit Forschungsdaten in einem ersten Schritt regeln soll. Auch die Frankfurt UAS hat eine solche Forschungsdaten-Policy verabschiedet. -
1.3 Vorteile eines guten Forschungsdatenmanagements
Doch welche Vorteile ergeben sich für Sie eigentlich durch ein gutes Forschungsdatenmanagement? Abbildung 1.3 schlüsselt in einem ersten Schritt die verschiedenen Ziele, die durch FDM verfolgt werden können, für verschiedene Dimensionen auf.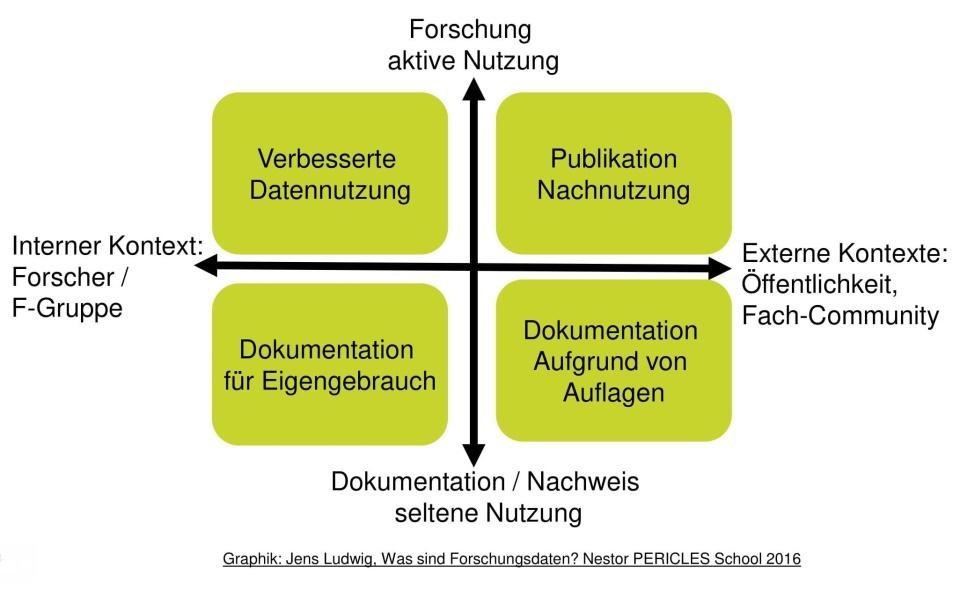
Abb. 1.3: Ziele des FDM für verschiedene Dimensionen
Die Ziele werden durch unterschiedliche Dimensionen (interner/externer Kontext; aktive/seltene Nutzung der Daten) beeinflusst. Forschungsdatenmanagement soll die Forschenden in Umgang und Nachvollziehbarkeit ihrer Daten selbst unterstützen (die zwei linken Quadranten) sowie den Ansprüchen der Öffentlichkeit genügen (die zwei rechten Quadranten). Weiterhin soll es dafür sorgen, dass generierte Daten aktiv zur weiteren Forschung genutzt werden können (obere Quadranten), sowie zur langfristigen Qualitätssicherung in Form einer Dokumentation des Forschungsprozesses (untere Quadranten) (vgl. Broschard und Wellenkamp 2019: Abschnitt Vorteile von Forschungsdatenmanagement).
Forschungsdatenmanagement soll durch geeignete Dokumentation des Forschungsprozesses zur langfristigen Nachvollziehbarkeit und Reproduzierbarkeit der Daten führen und Datenverlust minimieren. Die Transparenz der Datenerhebung und -verarbeitung wird so gefördert und eine Validierung der Forschungsergebnisse z. B. im Falle von Anschuldigungen wird des Weiteren erleichtert. Auf lange Sicht gesehen, werden bei erfolgreichem Forschungsdatenmanagement Zeit und Ressourcen gespart. Gründe dafür sind beispielsweise eine bessere Zusammenarbeit (z. B. durch gemeinsame Standards, Nutzung gemeinsamer Plattformen usw.), die Vermeidung von Fehlern und eine Absicherung gegen Datenverlust.
Neben diesen praktischen Vorteilen während der Forschung bringt eine Publikation gut dokumentierte und nachnutzbarer Datensätze eine Steigerung der Sichtbarkeit und Reputation für Sie als Forscher mit sich, da zunehmend nicht nur wissenschaftliche Fachartikel, sondern auch Datenpublikationen mit immer weiter steigender Tendenz gewürdigt werden.
-
-
Hier sind noch einmal die wichtigsten Fakten zum Kapitel zusammengefasst.
-
Bearbeitungsdauer: 9 Minuten, 45 Sekunden
-
2.2 Der Forschungsdatenlebenszyklus
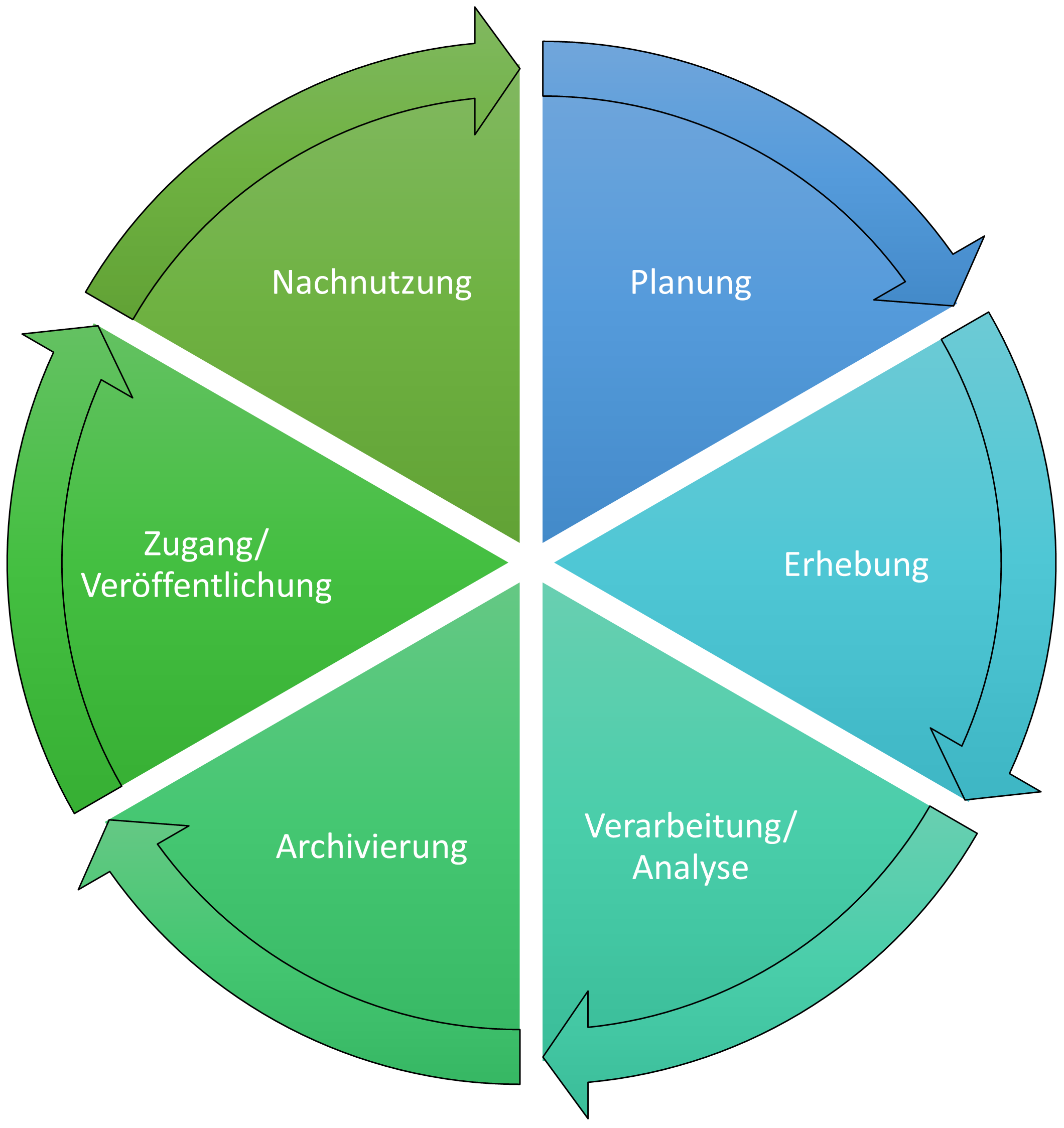
Abb. 2.1: Der Forschungsdaten Lebenszyklus (angelehnt an das DCC Curation Lifecycle Model)
Der Forschungsdatenlebenszyklus ist eine Visualisierung des Forschungsprozesses, bei der speziell die Rolle der Daten in den Blick genommen wird. Er zeigt, dass ein professioneller Umgang mit Forschungsdaten mehr beinhaltet als nur Erhebung und Analyse. Als Forscher*in lohnt es sich, in Entscheidungen immer alle Phasen mitzudenken und sich schon frühzeitig zu informieren, welche Tools und Möglichkeiten es gibt, um Ihre Praxis im Umgang mit Forschungsdaten zu optimieren.
-
2.3 Einzelne Schritte im Forschungsdatenlebenszyklus
Im Folgenden werden die einzelnen Phasen näher betrachtet und es wird beschrieben, was Sie mit Blick auf das Forschungsdatenmanagement im Einzelnen tun können.
1. Planung
“Wer scheitert zu planen, der plant zu scheitern.” - Benjamin Franklin
Nur mit guter Planung können auch gute Ergebnisse erzielt werden. Dies erfordert reifliche Überlegung, Absprachen und Recherchen. In Bezug auf das Forschungsdatenmanagement verlangen viele Forschungsförderer bereits bei der Antragsstellung einen sogenannten Datenmanagementplan (siehe Kapitel 3). Doch auch ohne explizite Vorgaben lohnt es sich, bereits im Vorfeld genau schriftlich festzuhalten, wie mit den Daten umgegangen werden soll. Das schafft Verbindlichkeit und Einheitlichkeit (insb. bei Projekten mit mehreren Beteiligten) und kann als Nachschlagewerk, Checkliste und Dokumentation dienen.
Insgesamt können für die Planung folgende Aspekte relevant sein:
- Untersuchungsdesign festlegen
- Projektteam zusammenstellen und Rollen klären
- Zeitplan aufstellen
- Datenmanagement planen (Formate, Speicherorte, Dateibenennung, kollaborative Plattformen, etc.)
- bereits existierende Literatur und Daten sichten
- ggf. Nachnutzung vorhandener Daten
- Urheberschaft und Datenbesitz klären
- Zugriffsmöglichkeiten und -bedingungen abstimmen
2. Erhebung
Die Datenerhebung kann mitunter einen erheblichen Teil der Forschungsarbeiten ausmachen. Zudem ziehen sich Fehler in dieser Phase durch den gesamten weiteren Forschungsprozess und führen im schlimmsten Fall unbemerkt zu falschen Ergebnissen. Umso wichtiger ist es, bei der Erhebung besondere Sorgfalt walten zu lassen. Neben den eigentlichen Daten betrifft dies vor allem die Dokumentation der durchgeführten Forschungsarbeiten sowie eine (möglichst standardisierte) Erfassung von Metadaten. Letzteres sind strukturierte, weiterführende Informationen über Ihre Daten, welche in Kapitel 4 näher beschrieben werden.
Insgesamt sollte die Datenerhebung folgende Aspekte umfassen:
- Durchführung der Experimente, Beobachtungen, Messungen, Simulationen etc.
- Erzeugung von digitalen Rohdaten (z. B. durch Digitalisieren oder Transkribieren)
- Speicherung der Daten in einem einheitlichen Format
- Sicherung (Backup) und Verwaltung der Daten
- Erfassung und Erstellung von Metadaten
- Dokumentation der Datenerhebung
3. Verarbeitung / Analyse
Bei der Analyse Ihrer Daten kennen Sie sich am besten aus. Hierbei ist es wichtig, dass Sie die in Ihrem Bereich üblichen Standards und Methoden anwenden und diese auch dokumentieren.
Für Sie selbst und vor allem in der Zusammenarbeit mit anderen ist es wichtig, dass Sie ein System der Dateibenennung, Versionierung und Datenorganisation haben. Als Unterstützungsleistung können Kollaborationsplattformen dienen. Weitere Informationen hierzu erhalten Sie in den Kapiteln 6 und 7.
Insgesamt können Sie bei der Datenverarbeitung und -analyse folgende Aspekte berücksichtigen:
- Daten prüfen, validieren, bereinigen (Qualitätssicherung)
- Daten ableiten, aggregieren, harmonisieren
- Fachspezifische Standards nutzen (z. B. hinsichtlich Methoden und Dateiformaten)
- Nutzung der Daten in wissenschaftlichen Publikationen vorbereiten
- Datenverarbeitung dokumentieren (zum späteren Verständnis)
- Kooperationsplattformen zum Datenaustausch mit (Fach-)Kolleg*innen nutzen
- Analysen durchführen
- Daten interpretieren
4. Archivierung
Im Kodex zur "Sicherung guter wissenschaftlicher Praxis" (2019) der Deutschen Forschungsgemeinschaft beschreibt Leitlinie 17, dass "[Rohdaten] in der Regel für einen Zeitraum von zehn Jahren zugänglich und nachvollziehbar in der Einrichtung, wo sie entstanden sind, oder in standortübergreifenden Repositorien aufbewahrt" werden sollen. Dies dient der wissenschaftlichen Qualitätssicherung und ermöglicht die langfristige Überprüfbarkeit wissenschaftlicher Erkenntnisse. Zudem können die Daten ggf. von anderen Wissenschaftler*innen nachgenutzt werden.
Um eine tatsächliche Nachnutzung zu ermöglichen, müssen jedoch einige Voraussetzungen erfüllt sein:
- Verständlichkeit
- langlebige, am besten nicht-proprietäre (d. h. kostenlos und Open Source) Dateiformate
- langlebige Speichermedien
- Auffindbarkeit
Es bietet sich daher an, auf professionelle Archivierungsdienste zurückzugreifen. Was Sie in Bezug auf die Archivierung Ihrer Forschungsdaten noch beachten sollten, lernen Sie in Kapitel 8.
5. Zugang / Veröffentlichung
Neben der (Text-)Publikation in wissenschaftlichen Zeitschriften werden auch die Daten, auf denen sie basieren, immer gefragter. Viele Forschungsförderer und Journals verlangen mittlerweile sogar eine explizite Datenpublikation. Dadurch kann zusätzlich eine Qualitätssicherung stattfinden und, wenn andere Forschende mit Ihren Daten arbeiten, erhalten Sie durch Zitationen einen Reputationsgewinn.
Grundsätzlich gibt es drei Arten der Veröffentlichung von Forschungsdaten (Biernacka et al., 2018):
- Als Beigabe zu einem wissenschaftlichen Fachartikel (= data supplement)
- Als eigenständige Veröffentlichung in einem Repositorium (= langfristiger Speicherort für Daten)
- Als Artikel in einem Data Journal:
Dies sind (in der Regel) peer-reviewte Paper, die Datensätze mit hohem Wiederverwendungswert vorstellen und näher beschreiben. Die Daten selbst sind meist in einem Forschungsdatenrepositorium veröffentlicht.
Für die Suche nach einem geeigneten Repositorium eignet sich das Portal https://www.re3data.org/. Wichtig ist, dass das gewählte Repositorium die FAIR-Prinzipien für Forschungsdaten erfüllt (forschungsdaten.org 2018). Weitere Informationen hierzu finden Sie in Kapitel 5.
6. Nachnutzung
Bei der Weitergabe und Veröffentlichung von Forschungsdaten sollten Sie darauf achten, dass diese auch tatsächlich nachgenutzt werden können. Dies eröffnet vielfältige Möglichkeiten:
- weitere Untersuchungen mit vorhandenen Daten (Sekundärdatenanalyse)
- Überprüfung von Ergebnissen (Replikation, Qualitätssicherung)
- Verknüpfung mit anderen Daten (Record Linkage)
- Nutzung in der praxisbezogenen Lehre
Voraussetzung für die Nachnutzung ist die Vergabe einer entsprechenden Nutzungslizenz. Häufig werden dabei Creative Commons Lizenzen verwendet. Im Geiste von Open Science sollten diese möglichst offen gewählt werden.
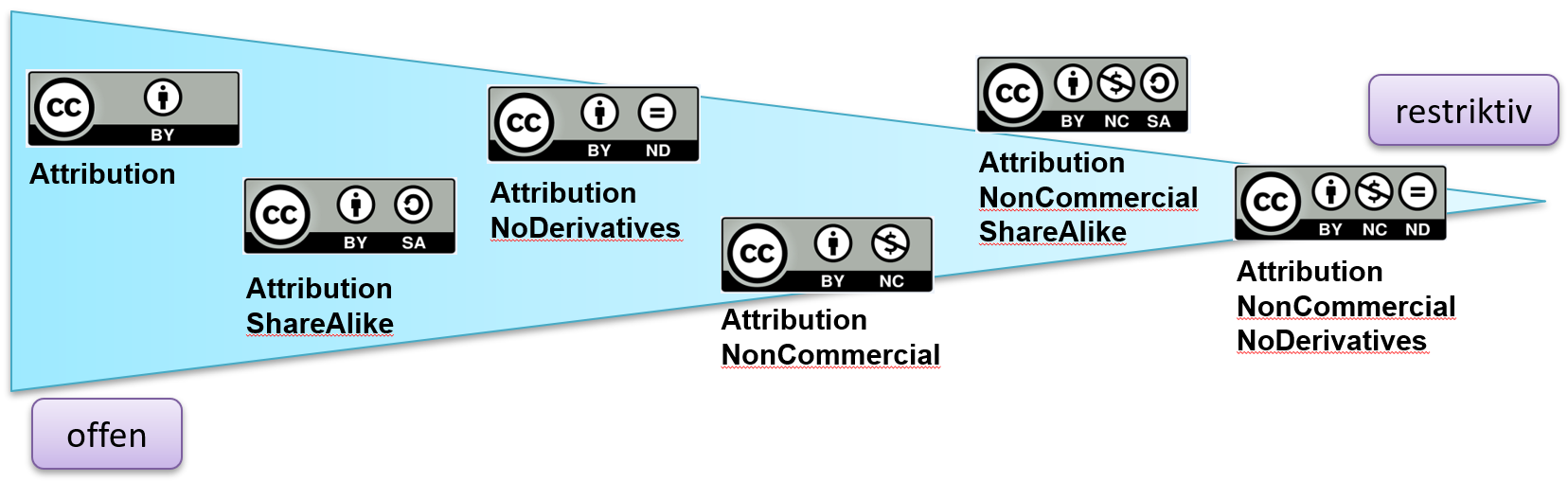
Abb. 2.2: Überblick über Creative Commons Lizenzen, Quelle: Apel et al. 2017, S. 57
Des Weiteren ist es wichtig, dass die Daten eine gute Qualität (vollständig, fehlerfrei, bereinigt, lückenlos) aufweisen und hinreichend dokumentiert sind. Zudem spielen Dateiformate eine wichtige Rolle. Diese sollten möglichst weit verbreitet und nicht-proprietär sein. Ggf. kann auch eine doppelte Ablage der Daten (einmal im Original- und einmal in einem offenen Format) sinnvoll sein. Eine Übersicht über geeignete Dateiformate finden Sie beispielsweise bei forschungsdaten.info.
Damit Daten langfristig gefunden und korrekt zitiert werden können, bietet sich die Verwendung von Persistenten Identifikatoren (PID) an. Sie verweisen dauerhaft auf einen bestimmten Inhalt (z. B. Datensatz) und eignen sich somit hervorragend für Zitationen. Ein Weblink kann sich ändern, ein PID bleibt immer gleich. Zwei Arten von PIDs können unterschieden werden:
- Identifier für digitale Objekte, z. B.
DOI = Digital Object Identifier
URN = Uniform Resource Name - Identifier für Personen (eindeutige wissenschaftliche Identität), z. B.
ORCID = Open Researcher Contributor Identification
ResearcherID
Repositorien und Journals vergeben automatisch entsprechende Identifikatoren für die dort eingereichten Daten/Beiträge. Besitzen Sie zudem einen Personenidentifier (wie bspw. ORCID), können Ihre Werke automatisch mit Ihrem Profil verknüpft werden und Sie bekommen bei jeder Nachnutzung die Zitation zugeschrieben. -
-
Hier sind noch einmal die wichtigsten Fakten zum Kapitel zusammengefasst.
-
Bearbeitungsdauer: 11 Minuten, 12 Sekunde
Bearbeitungsdauer (ohne Video): 5 Minuten, 53 Sekunden-
3.1 Einführung & Lernziele
Bevor Sie mit Ihrem Forschungsvorhaben starten, sollten Sie sich einmal grundlegend damit auseinandersetzen, welche Art von Daten Ihr Projekt hervorbringt und wie Sie mit diesen umgehen wollen. Dabei sollten Sie unbedingt auch über den Abschluss Ihrer Forschung hinaus denken (siehe Kapitel 8). Die Ergebnisse Ihrer Überlegungen halten Sie in einem Datenmanagementplan (kurz DMP) fest. Ein DMP hilft Ihnen dabei, langfristig das Beste aus Ihren Daten herauszuholen. Das wissen auch die Drittmittelgeber und verlangen häufig einen DMP.
Nach Abschluss dieses Kapitels können Sie...
- ...erklären, was ein DMP ist
- ...benennen, welche Informationen ein DMP enthält
- ...den Nutzen erkennen, den Sie aus einem DMP ziehen
- ...Tools finden, die Ihnen beim Erstellen eines DMP helfen
Einen guten ersten Überblick über Datenmanagementpläne bietet dieses Video der RWTH Aachen.
-
-
Hier sind noch einmal die wichtigsten Fakten zum Kapitel zusammengefasst.
-
-
Bearbeitungsdauer: 24 Minuten, 12 Sekunden
-
4.3 Wie sehen Metadaten aus?
Metadaten liegen immer in einer bestimmten inneren Struktur vor, wenn auch die tatsächliche Umsetzung in verschiedenen Formen (z. B. von einem einfachen Textdokument über eine Tabellenform bis hin zu einer sehr stark formalisierten Form als XML-Datei, die einem bestimmten Metadatenstandard folgt) geschehen kann. Die Struktur selbst ist abhängig von den zu beschreibenden Daten (beispielsweise Nutzung von Kopfzeilen und Legenden in Excel-Tabellen im Vergleich zur formalisierten Beschreibung eines literarischen Werkes in einem OPAC), der intendierten Nutzung und den verwendeten Standards. Ganz allgemein gesagt, beschreiben Metadaten (digitale) Objekte formalisiert und strukturiert. Zu solchen digitalen Objekten gehören auch Forschungsdaten. Speziell auf unseren Anwendungsfall bezogen, kann man sagen, dass Metadaten das eigene Forschungsvorhaben und damit zusammenhängende Forschungsdaten formalisiert und strukturiert beschreiben.
Es ist sinnvoll, aber nicht zwingend notwendig, dass Metadaten nicht nur vom Menschen, sondern auch von Maschinen lesbar sind, damit Forschungsdaten maschinell und automatisiert verarbeitet werden können. Unter Maschinen sind hier vor allem Computer zu verstehen, weshalb man genauer auch von einer Lesbarkeit durch einen Computer sprechen kann. Um diese zu erreichen, müssen die Metadaten in einer maschinenlesbaren Auszeichnungssprache vorliegen. Häufig werden dafür forschungsspezifische Standards in der Auszeichnungssprache XML (Extensible Markup Language) verwendet, es gibt aber auch andere wie beispielsweise JSON (JavaScript Object Notation). Bei der Einreichung von (Forschungsdaten-)Publikationen gibt es in den meisten Fällen die Möglichkeit, die Metadaten direkt in ein vorgefertigtes Online-Formular einzutragen. Eine genaue Kenntnis von XML, JSON oder anderen Auszeichnungssprachen ist bei der Erstellung von Metadaten zum eigenen Projekt also nicht zwangsläufig erforderlich, kann aber zum Verständnis, wie die Forschungsdaten verarbeitet werden, beitragen.
Die Lesbarkeit durch Computer ist ein wesentlicher Punkt und wird beispielsweise dann wichtig, wenn verwandte Forschungsdaten durch Schlagwortsuche gefunden oder miteinander verglichen werden sollen. Eine maschinenlesbare Datei kann mithilfe von speziellen Programmen erstellt werden. Im Abschnitt "Wie erstelle ich meine Metadaten" bekommen Sie entsprechende Programme vorgestellt.
Besteht keine Kenntnis in der Erstellung von maschinenlesbaren Metadaten-Dateien, sollten Sie die Metadaten zu Ihren Forschungsdaten in einer für Sie möglichen Form abspeichern. Hierfür kann beispielsweise auch eine einfache Text-Datei über den integrierten Editor ihres Betriebssystems erstellt werden, in der jede Zeile eine Information enthält. Überlegen Sie dabei, welche Informationen für die Nachvollziehbarkeit wichtig sind (z. B. Ersteller*in der Daten, Datum der Erstellung/des Versuchs, Aufbau einzelner Versuchsanordnungen usw.). Welche Kategorien beschrieben werden müssen, hängt meist stark von Art, Umfang und Struktur der Forschungsdaten ab. Eine Übertragung in eine maschinenlesbare Form ist bei ordentlicher und nachvollziehbarer Dokumentation am Ende eines Projekts bzw. eines Teilabschnitts des Projekts immer noch möglich.
Beispiele für Metadaten
Im Folgenden soll anhand einiger Beispiele gezeigt werden, wie Metadaten aussehen können.
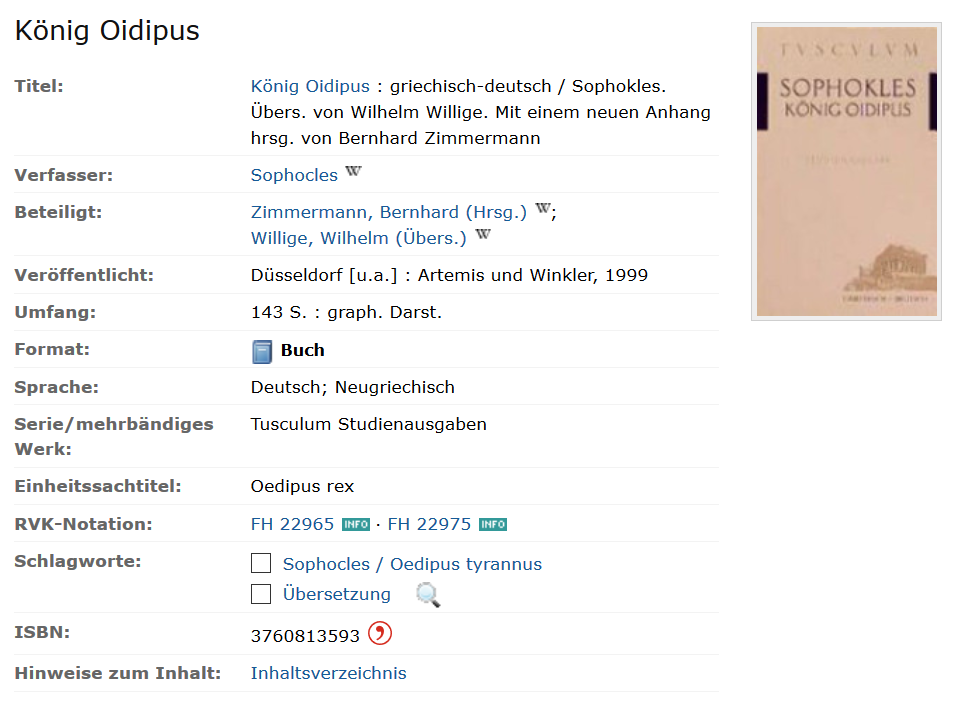
Abb. 4.1: Eintrag eines Werks in einem Online-Bibliothekskatalog, Quelle: https://hds.hebis.de/ubgi/Record/HEB060886269Abbildung 4.1 zeigt einen Buchtitel als Eintrag in einem Online-Bibliothekskatalog in einer Form, wie Sie als Angehörige einer Hochschule dies vermutlich schon des Öfteren gesehen haben. An dieser Stelle sei angemerkt, dass Metadaten keine neuartige Entwicklung darstellen und nicht erst im digitalen Zeitalter eine tragende Rolle spielen, sondern schon vorher beispielsweise beim Anlegen von Zettelkatalogen in Bibliotheken verwendet wurden, um Bücher wiederzufinden. Die in Abbildung 4.1 untereinander aufgelisteten Informationen stellen ebenfalls nichts Anderes als Metadaten dar, die aufbereitet von einem Verarbeitungssystem auch von Nutzern gelesen werden können, um Informationen über ein bestimmtes Werk zu bekommen. Sie erfahren etwas über den Titel, den*die Verfasser*in*nen, den Umfang, Angaben zum Veröffentlichungsjahr, der Sprache usw.
Auch wenn sich die Daten aus dem obigen Beispiel wahrscheinlich in hohem Maße von Ihren Forschungsdaten unterscheiden, lässt sich die Art, wie Metadaten erfasst werden, daran gut erläutern. Würde man Metadaten für Forschungsdaten in dieser Art und Weise verfassen, wie sie hier für den Nutzer erscheint, nämlich in einer Art zweispaltigen Tabelle, wobei eine Spalte die Kategorie (z. B. Titel) und eine andere Spalte die tatsächliche Information (hier „König Oidipus“) enthält, wären diese Informationen für einen späteren Forschenden für das Verständnis der Daten in jedem Falle hilfreich. Es würde aber noch nicht dazu führen, dass Computersysteme diese Daten auch automatisiert verarbeiten können.
Sollten Sie also mit der Aufbereitung von computerlesbaren Metadaten überhaupt keine Erfahrung haben, lohnt es sich, wie zuvor schon erwähnt, eine derartige tabellarische Auflistung aller relevanten Daten in einer Datei (z. B. .docx, .xlsx, .txt, o. ä.) schon zu Beginn eines Forschungsvorhabens zu nutzen und durchgehend aktuell zu halten, um bei einer möglichen späteren Einreichung diese Daten schon zur Hand zu haben. Halten Sie sich dabei auch an ein sinnvolles Versionierungskonzept, um Änderungen in den Daten im Laufe der Projektlaufzeit nachvollziehbar zu machen (siehe Kapitel 8). Abb. 4.2: Maschinenlesbare Beispiel-Metadaten gemäß dem Dublin Core Metadata Element Set, Quelle: Henrike Becker, Projekt „FOKUS“Abbildung 4.2 zeigt einen Teil eines maschinenlesbaren Metadatensatzes, der gemäß den Konventionen des Dublin Core Metadata Element Set, welches 1995 von der Dublin Core Metadata Initiative erstmals veröffentlicht wurde, in der Auszeichnungssprache XML verfasst ist (mehr dazu in Abschnitt 4.4 – „Was sind Metadatenstandards?“). Woran das erkennbar ist, wird im Folgenden erläutert.Alles, was in Abbildung 4.2 in blauer Schrift verfasst ist, bezeichnet man als Elemente, alles in schwarzer Schrift ist der Inhalt dieser Elemente. Ein einfacheres Verständnis dieses Verhältnisses ergibt sich, wenn man noch einmal Abbildung 4.1 betrachtet: Die linke Spalte ist dort die Art der Information bzw. Kategorie (also bspw. „Titel“, „Verfasser“ usw.), die rechte Spalte dann die tatsächliche Information innerhalb dieser Kategorie (also beispielsweise „König Oidipus“, „Sophocles“ usw.). Das Verhältnis von Element und Inhalt des Elements verhält sich analog, wobei die Art der Information/Kategorie die Elemente (blaue Schrift in Abbildung 4.2) und die tatsächliche Information den Inhalt der Elemente (schwarze Schrift in Abbildung 4.2) darstellen.Ein grundlegender Unterschied ist jedoch der Aufbau: Elementnamen stehen immer in einer Klammerung durch Kleiner-als- und Größer-als-Zeichen (z. B. „<…>“). Außerdem gibt es für jede Kategorie jeweils ein öffnendes und ein schließendes Element. Das öffnende Element ist erkennbar an dem Kleiner-als-Zeichen „<“ und steht immer vor der tatsächlichen Information. Das schließende Element ist erkennbar an dem Schrägstrich „/“ nach dem Kleiner-als-Zeichen „<“ und steht immer hinter der tatsächlichen Information der jeweiligen Kategorie. Diese öffnenden und schließenden Elemente umschließen also praktisch immer den dazwischenliegenden Informationsgehalt, was in Abbildung 4.2 leicht erkennbar ist. Innerhalb der Kleiner-als- und Größer-als-Zeichen steht die Angabe über die Kategorie (z. B. „title“, „creator“) usw. Die schwarz geschriebene Information zwischen <dc:creator> und </dc:creator> gibt Ihnen also beispielsweise Auskunft über den Urheber des jeweiligen Dokuments bzw. der jeweiligen Daten. Im Falle von Abbildung 4.2 wäre dies „Henrike Becker“.
Abb. 4.2: Maschinenlesbare Beispiel-Metadaten gemäß dem Dublin Core Metadata Element Set, Quelle: Henrike Becker, Projekt „FOKUS“Abbildung 4.2 zeigt einen Teil eines maschinenlesbaren Metadatensatzes, der gemäß den Konventionen des Dublin Core Metadata Element Set, welches 1995 von der Dublin Core Metadata Initiative erstmals veröffentlicht wurde, in der Auszeichnungssprache XML verfasst ist (mehr dazu in Abschnitt 4.4 – „Was sind Metadatenstandards?“). Woran das erkennbar ist, wird im Folgenden erläutert.Alles, was in Abbildung 4.2 in blauer Schrift verfasst ist, bezeichnet man als Elemente, alles in schwarzer Schrift ist der Inhalt dieser Elemente. Ein einfacheres Verständnis dieses Verhältnisses ergibt sich, wenn man noch einmal Abbildung 4.1 betrachtet: Die linke Spalte ist dort die Art der Information bzw. Kategorie (also bspw. „Titel“, „Verfasser“ usw.), die rechte Spalte dann die tatsächliche Information innerhalb dieser Kategorie (also beispielsweise „König Oidipus“, „Sophocles“ usw.). Das Verhältnis von Element und Inhalt des Elements verhält sich analog, wobei die Art der Information/Kategorie die Elemente (blaue Schrift in Abbildung 4.2) und die tatsächliche Information den Inhalt der Elemente (schwarze Schrift in Abbildung 4.2) darstellen.Ein grundlegender Unterschied ist jedoch der Aufbau: Elementnamen stehen immer in einer Klammerung durch Kleiner-als- und Größer-als-Zeichen (z. B. „<…>“). Außerdem gibt es für jede Kategorie jeweils ein öffnendes und ein schließendes Element. Das öffnende Element ist erkennbar an dem Kleiner-als-Zeichen „<“ und steht immer vor der tatsächlichen Information. Das schließende Element ist erkennbar an dem Schrägstrich „/“ nach dem Kleiner-als-Zeichen „<“ und steht immer hinter der tatsächlichen Information der jeweiligen Kategorie. Diese öffnenden und schließenden Elemente umschließen also praktisch immer den dazwischenliegenden Informationsgehalt, was in Abbildung 4.2 leicht erkennbar ist. Innerhalb der Kleiner-als- und Größer-als-Zeichen steht die Angabe über die Kategorie (z. B. „title“, „creator“) usw. Die schwarz geschriebene Information zwischen <dc:creator> und </dc:creator> gibt Ihnen also beispielsweise Auskunft über den Urheber des jeweiligen Dokuments bzw. der jeweiligen Daten. Im Falle von Abbildung 4.2 wäre dies „Henrike Becker“.An dieser Stelle sollen noch kurz die anderen in Abbildung 4.2 gezeigten Elemente erklärt werden. Das <dc:title>-Element beinhaltet den Titel unter dem das Dokument oder der Forschungsdatensatz veröffentlicht wurde. Systeme, die Titel aus einer Datenbank auslesen und anzeigen, nutzen oftmals den Inhalt dieses Elements als Information. <dc:subject> kann mehrfach vorkommen und beinhaltet immer ein Thema des Inhalts in Keywords, die als Suchgrundlage dienen. Das zweite <dc:subject>-Element in Abbildung 4.2 beinhaltet eine sehr lange Angabe eines Themas (also nicht nur Keywords), die eher vermieden werden sollte, damit bessere Suchergebnisse erzielt werden können. Das Element <dc:description> gibt eine Kurzzusammenfassung des Inhalts. Handelt es sich um Textpublikationen kann dort auch das Inhaltsverzeichnis untergebracht werden. Auch bei diesem Element sind Mehrfachnennungen möglich. <dc:date> beinhaltet ein Datum, meistens das der Veröffentlichung. Das Datum sollte, wenn es möglich ist, zur besseren Durchsuchbarkeit in Notation nach DIN ISO 8601 als JJJJ-MM-TT vorliegen. Innerhalb dieses Elements können Unter-Elemente (sogenannte Kind-Elemente) untergebracht werden, die schließlich genauere Informationen zum Datum geben, etwa, ob es sich um das Erstellungsdatum, das Datum der letzten Änderung oder das Veröffentlichungsdatum handelt. Das Element <dc:identifier> ist nur einmalig und obligatorisch in einem Metadatensatz vorhanden. Der darin enthaltene persistente Identifier ist weltweit nur einmal vergeben und weist das Dokument oder den Forschungsdatensatz eindeutig aus. Nähere Informationen zu persistenten Identifiern gibt es im folgenden Abschnitt „Welche Kategorien sind wichtig?“ sowie im Abschnitt „Findable“ von Kapitel 5.
Die zwei Buchstaben mit dem Doppelpunkt „dc:“, die in den Elementen vor dem eigentlichen Elementnamen „creator“ usw. stehen, zeigen, dass es sich bei den Elementen um Elemente aus dem anfangs erwähnten Dublin Core Metadata Element Set handelt. Genauere Informationen, warum diese beiden Buchstaben davor geschrieben werden sollten bzw. oft sogar müssen, werden im Abschnitt 4.4 – „Was sind Metadatenstandards?“ genauer erläutert.
Und nun sind Sie an der Reihe. Was sind bei der dargestellten Tabelle Daten und was sind Metadaten? Zur Auflösung klicken Sie auf das Bild.
 Abb. 4.3: Daten und Metadaten einer Excel-Tabelle
Abb. 4.3: Daten und Metadaten einer Excel-TabelleWelche Kategorien sind wichtig?
Es gibt sehr viele verschiedene Kategorien, die durch Metadaten beschrieben werden können und oft auch müssen. Je nach Disziplin und Forschungsdaten können sich diese Kategorien stark unterscheiden, manche gelten aber als Standardkategorien für alle Disziplinen.
Eine Kategorie, die spätestens im Falle einer zitierfähigen Veröffentlichung in den Metadaten vorhanden sein sollte, ist der im vorigen Abschnitt erwähnte „Persistent Identifier“. Ein Identifier dient der dauerhaften und unverwechselbaren Identifizierung. Bekannt und häufig verwendet ist der DOI (Digital Object Identifier). Ein DOI wird durch offizielle Registrierungsstellen, wie beispielsweise DataCite, vergeben. Metadaten sind über einen DOI mit dem Dokument und den Forschungsdaten verknüpft. Über einen DOI werden Forschungsdaten zitierbar. Die Zitationsvorgaben müssen in den Metadaten ebenfalls eindeutig festgelegt werden, um der guten wissenschaftlichen Praxis gerecht zu werden.
Weiterhin sollte aus den Metadaten hervorgehen, wer der*die Verfasser*in der Daten ist. Bei Gruppen von Forschenden sollten alle Beteiligten genannt werden, die an der Arbeit beteiligt waren oder eventuelle Rechte an den Forschungsdaten haben. Zu Letzteren können natürlich auch Firmen gehören, die vielleicht zur Förderung der Forschung beigetragen haben. Dabei sollte auf eine vollständige und eindeutige Namensnennung geachtet werden. Falls eine ForscherID (bspw. ORCID) vorliegt, sollte diese genannt werden.
Der Forschungsgegenstand sollte so ausführlich wie nötig beschrieben werden. Hierbei kann es mit Blick auf die Auffindbarkeit der Forschungsdaten auch sinnvoll sein, bereits Schlagwörter zu nennen, die dann bei einer digitalen Datenbank-Suche hinzugezogen werden können, um bessere Treffer zu erzielen.
Außerdem werden für die Nachvollziehbarkeit der Forschungsdaten eindeutige Informationen für Parameter wie Ort, Zeit, Temperatur, soziales Setting,... und alle anderen für die Daten sinnvollen Bedingungen benötigt. Dazu gehören auch benutzte Instrumente und Geräte mit deren genauen Konfigurationen.
Wurde zur Erstellung der Forschungsdaten bestimmte Software verwendet, muss auch der Name der Software in den Metadaten genannt werden. Dazu zählt natürlich auch die Nennung der verwendeten Softwareversion, da so spätere Forschende bei sehr alten Daten eher nachvollziehen können, warum diese Daten unter Umständen nicht mehr geöffnet werden können.
Manche Anforderungen an Metadaten sind immer gleich. Dies gilt auch für die gerade aufgelisteten Kategorien, die sehr generisch sind. Für solche Fälle existieren fachunabhängige Metadatenstandards, zu denen auch das bereits eingeführte Dublin Core Element Set gehört. Weitere Anforderungen können sich zwischen verschiedenen Disziplinen sehr stark unterscheiden. Daher existieren fachspezifische Standards, die diese Anforderungen abdecken. Mehr dazu erfahren Sie im nächsten Abschnitt 4.4 – „Was sind Metadatenstandards?“.
Abbildung 4.4 stellt verschiedene Kategorien von Metadaten dar, die sich im Hinblick auf Forschungsdaten als sinnvoll erweisen können.
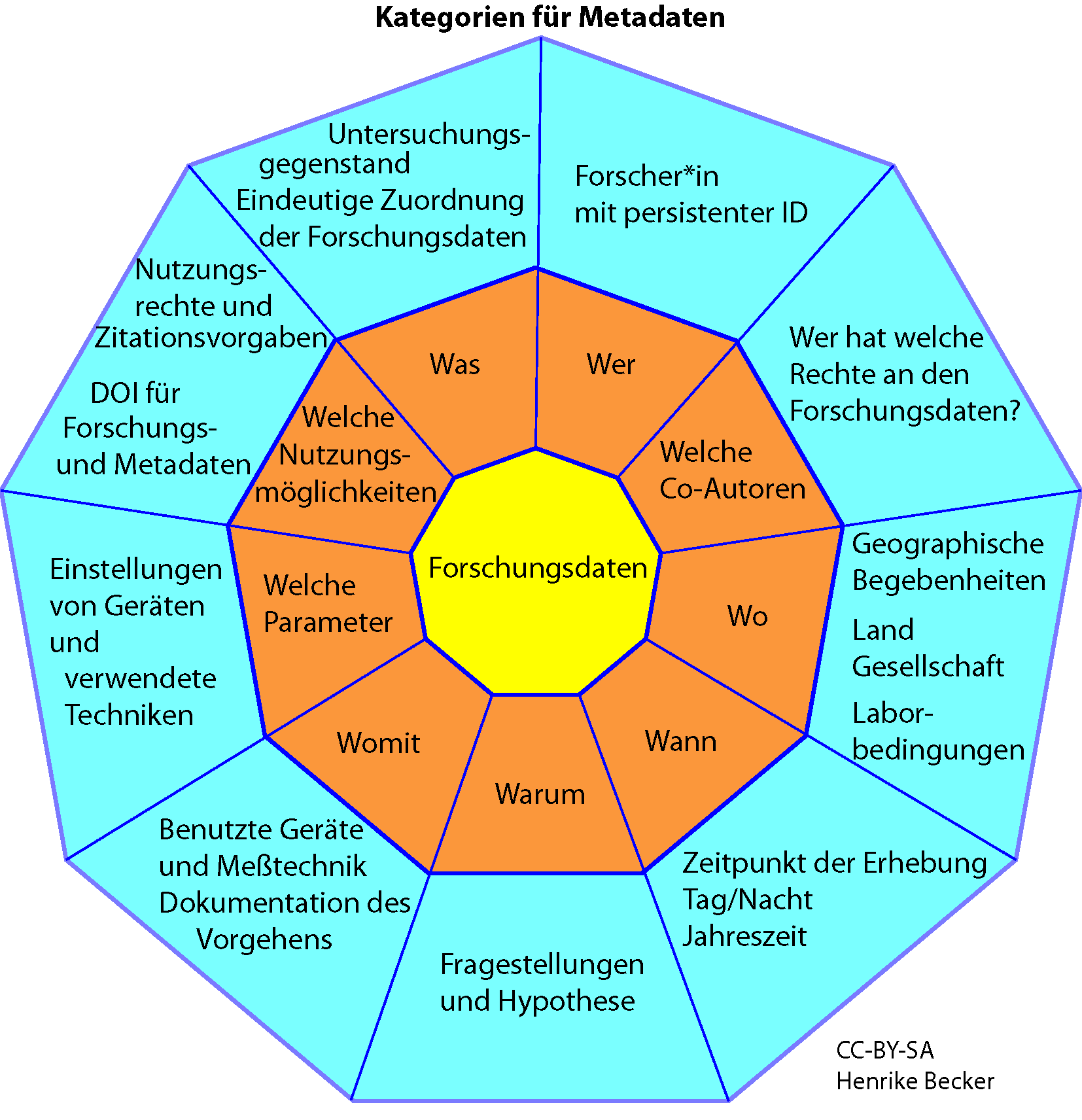
Abb. 4.4: Auflistung von Beispielkategorien, Quelle: Henrike Becker, Projekt „FOKUS“
-
-
Hier sind noch einmal die wichtigsten Fakten zum Kapitel zusammengefasst.
-
Bearbeitungsdauer: 14 Minuten, 4 Sekunden
-
5.4 Möglichkeiten der Umsetzung
Die FAIR-Prinzipien in jeder Hinsicht umzusetzen, ist ein anspruchsvolles Unterfangen. Um einen ersten Indikator dafür zu haben, wie FAIR Ihre Daten sind, können Sie das „FAIR self assessment tool“ der Australian Research Data Commons nutzen, welches Sie hier finden können.
Außerdem können Sie auf jeden Fall in der Auswahl eines Datenrepositoriums zur Ablage und Veröffentlichung ihrer Daten darauf achten, dass dieses eine „FAIR Compliance“-Auszeichnung besitzt. Dafür muss es die hier aufgeführten Anforderungen erfüllen:
- Die Datensätze (oder idealerweise die einzelnen Dateien eines Datensatzes) sind mit eindeutigen und dauerhaften Persistent Identifiers (z. B. DOIs) versehen
- Die Datenbank erlaubt das Hochladen intrinsischer Metadaten (z. B. Name der Autor*innen, Inhalt des Datensatzes, dazugehörige Publikationen) sowie von Metadaten, welche die*der Registrierende selbst definiert (z. B. Bezeichnungen von Variablen)
- Die Lizenzen (z. B. CC0, CC-BY, MIT), unter denen die Daten in dem Repositorium verfügbar gemacht werden können, müssen klar erkennbar sein oder vom Benutzer selbst ausgewählt werden können.
- Die Quelleninformationen inkl. Metadaten sind, selbst bei eingeschränkt zugänglichen Datensätzen, immer öffentlich verfügbar.
- Das Datenarchiv liefert eine Eingabemaske, die ein bestimmtes Format für die intrinsischen Metadaten vorschreibt (um die maschinelle Lesbarkeit/Kompatibilität zu gewährleisten)
- Die Datenbank verfügt über einen Plan für die langfristige Erhaltung der archivierten Daten
Quelle: Schweizerischer Nationalfonds. Data Management Plan (DMP) - Leitlinien für Forschende
Bei der Suche nach einem geeigneten Repositorium, das den FAIR-Datenprinzipien entspricht, können Sie auch auf den Repository Finder zurückgreifen. Wenn Sie die Option „See the repositories in re3data that meet the criteria of the FAIRsFAIR Project“ aktivieren, erhalten Sie eine Übersicht über zertifizierte Repositorien, die Open Access und persistente Identifikatoren für die abzulegenden Daten anbieten. Für die Suche greift der Repository Finder auf das Registry of Research Data Repositories (re3data) zurück. Es bietet einen guten Überblick über internationale Forschungsdatenrepositorien in einer Vielzahl von wissenschaftlichen Disziplinen.
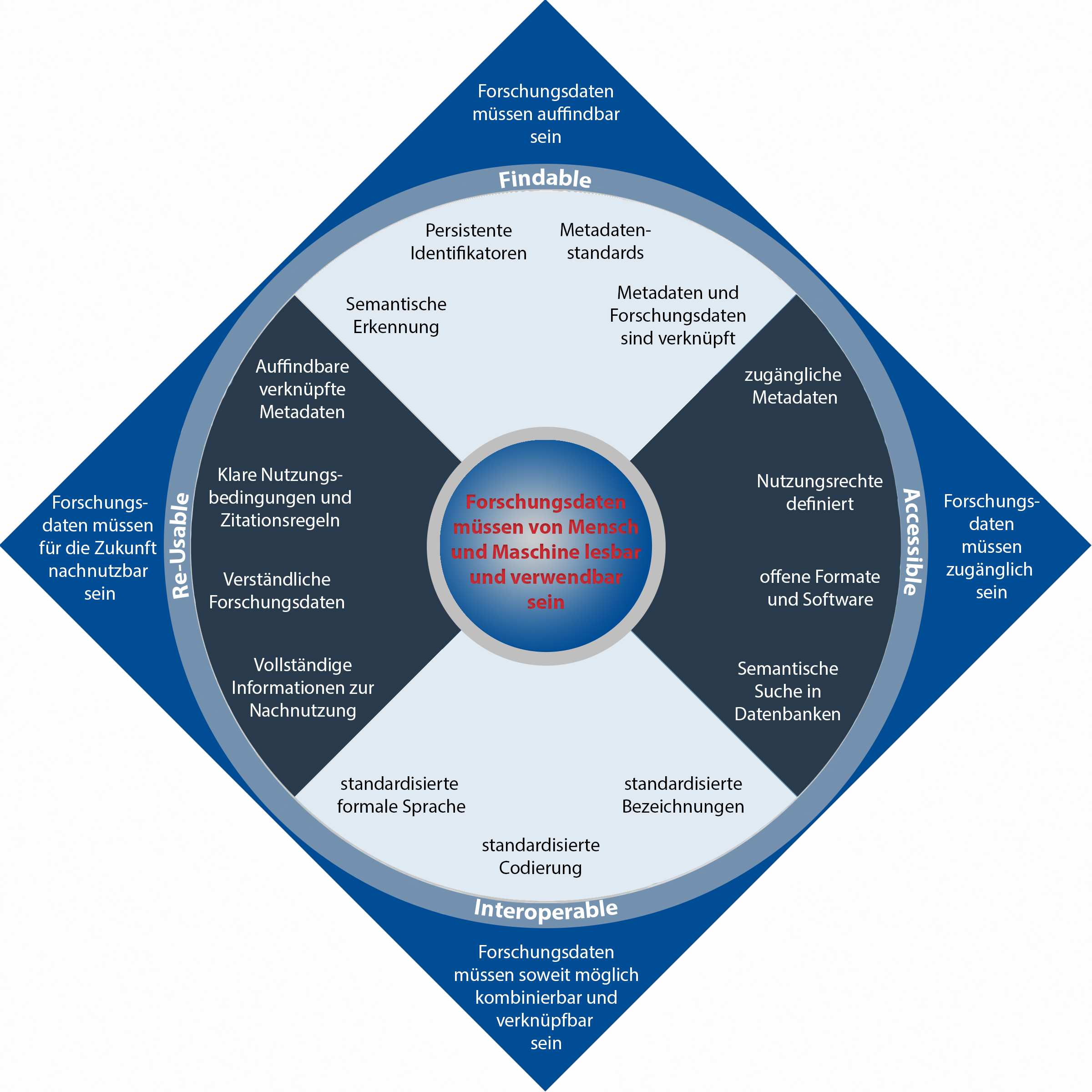
Abb. 5.1: Die Inhalte der FAIR-Prinzipien. Quelle: Henrike Becker, grafisch angepasst durch Andre Pietsch
-
-
Hier sind noch einmal die wichtigsten Fakten zum Kapitel zusammengefasst.
-
Bearbeitungsdauer: 13 Minuten, 47 Sekunden
Bearbeitungsdauer (ohne Video): 10 Minuten, 35 Sekunden-
6.2 Daten und Qualität – Welche Kriterien sind relevant?
Datenqualitätskriterien
Vielleicht möchten Sie eine auf Wohnort, also Postleitzahlen, basierte Untersuchung zum Diebstahlrisiko eines Autos vornehmen. Oder Sie wollen mittels eines Fragebogens herausbekommen, ob es einen Zusammenhang zwischen Studienerfolg und Abiturnoten gibt. In jedem Fall erheben Sie Daten, die Sie auswerten. Dazu müssen folgende Dimensionen der Datenqualität erfüllt ein, wobei je nach Ziel und Zweck einer Datenerhebung nicht alle Dimensionen gleichzeitig eine Rolle spielen.
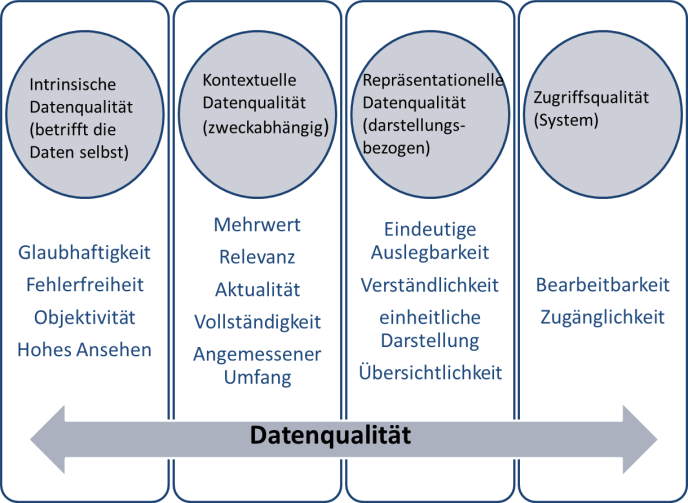
Abb. 6.1: Übersicht über Dimensionen der Datenqualität, Quelle: FOKUS
Diese Kriterien gehen zurück auf Richard Wang und Diane Strong (1996) und beschreiben Daten dann als qualitätsvoll, wenn sie von den Datennutzer*innen (dazu gehören auch Sie selbst) sowohl gegenwärtig als auch zukünftig als passend angesehen werden. Damit Forschungsdaten auch Jahre später interessant sind und nachgenutzt werden können, müssen die Daten so gründlich wie möglich beschrieben werden. Daher ist es wichtig, die Daten gut zu dokumentieren und Metadaten (siehe Kapitel 4) sowie ggf. erstellte und notwendige Forschungssoftware zum Öffnen und Betrachten der Dateien mitzuliefern.
Ein Beispiel – Datenqualitätskriterien und ihre Umsetzung
Am Beispiel der Erstellung einer Tabelle mit Unternehmensadressdaten werden die Kriterien der Datenqualität im Folgenden exemplarisch dargestellt. Mit Hilfe der Übersicht soll es möglich sein, schnelle Erkenntnisse über die Verteilung von Kunden nach Bundesländern zu gewinnen und Rechnungen gezielt an die richtigen Ansprechpersonen verschicken zu können.
Die Tabelle enthält die folgenden Merkmale:
- Interne Kundennummer
- Name des Unternehmens
- Straße
- Hausnummer
- Postleitzahl
- Ort
- Bundesland
- Nachname Ansprechpartner
- Vorname Ansprechpartner
- Telefonnummer
Das Ziel jeder wissenschaftlichen Unternehmung ist die Generierung von Wissen. In einem Prozess wird dieses aus Informationen gewonnen, die wiederum aus Daten abgeleitet werden. Damit dies geschehen kann, ist im vorliegenden Beispiel zunächst eine klare Benennung der Spalten wichtig. Erst daraus ergibt sich, dass eine bestimmte Folge von Zahlen und Symbolen (Daten) für einen bestimmten Sachverhalt (Information) steht. Selbst wenn die Zuordnung den Forschenden zum Zeitpunkt der Datenerhebung bekannt ist, sind diese Metadaten trotzdem notwendig, um die Datenerhebung auch in Zukunft verstehen zu können. Ebenso müssen natürlich auch die Daten selbst Qualitätskriterien erfüllen.
Die Kriterien im Einzelnen
Intrinsische Datenqualität:
- Glaubwürdigkeit: Hierfür müssen die Daten vertrauenswürdig und zuverlässig sein. Für unser Beispielvorhaben können Sie die Glaubhaftigkeit Ihrer Daten erhöhen, indem Sie erläutern, woher die Daten stammen.
- Fehlerfreiheit: Zur Fehlerfreiheit gehört die richtige Aufnahme der Daten. In unserem Beispiel wäre die Bezeichnung "Westfalen" falsch, denn die korrekte Bezeichnung lautet Nordrhein-Westfalen. Stammt der*die Kund*in tatsächlich aus dem Saarland, wäre auch die Bezeichnung Nordrhein-Westfalen fehlerhaft.
- Objektivität: Objektiv sind ihre Daten dann, wenn sie keine Wertungen enthalten. Im vorliegenden Beispiel würde z. B. ein Zusatz wie „schwieriger Mensch“ bei dem Vor- oder Nachnamen der Ansprechpartner das Kriterium der Objektivität verletzen.
- Hohes Ansehen: Hierbei geht es um die Reputation Ihrer Datenquelle. So können beispielsweise Daten, die Sie aus anderen Forschungsprojekten oder fachlichen Informationsportalen stammen als zuverlässiger angesehen werden als Daten von einem Datenbroker oder solche, die durch eine allgemeine Internetrecherche gesammelt wurden.
Kontextuelle Datenqualität:
- Mehrwert: Die Informationen bieten dann einen Mehrwert, wenn mit ihrer Hilfe die angestrebten Aufgaben erfüllt werden können. Im vorliegenden Beispielfall könnte das u. a. eine Abfrage zu allen Unternehmen in einem bestimmten Bundesland sein.
- Relevanz: Daten sind dann relevant, wenn sie dem Nutzer notwendige Informationen liefern. So hätten bspw. Kundendaten aus der Schweiz zwar einen Mehrwert an Informationen, jedoch keine Relevanz für die Verteilung der Unternehmen auf die deutschen Bundesländer.
- Aktualität: Ihre Daten sind dann aktuell, wenn sie einen entsprechenden Stand zeitnah abbilden. Im vorliegenden Beispiel würde eine vierstellige Postleitzahl nicht aktuell sein, da in Deutschland 1993 auf ein fünfstelliges System umgestellt wurde. Auskünfte über die Aktualität erhält man z. B. durch mitgelieferte Metadaten, Dokumentationsmaterialien oder Datumsangaben im Dokument selbst (Stand: __.__.____).
- Vollständigkeit: Ihre Daten sind dann vollständig, wenn keine Informationen fehlen. Wären in der Kundendatentabelle bspw. nur 10 der 16 Bundesländer enthalten oder gäbe es zu einigen der Kunden keine Adressdaten, bedeutete dies Einbußen in der Vollständigkeit.
- Angemessener Umfang: Die Daten liegen dann in einem angemessenen Umfang vor, wenn die gestellten Anforderungen mit der Menge an vorliegenden Daten umgesetzt werden können. In unserem Beispiel heißt das, dass für das Ziel, Rechnungen zu verschicken, Adressdaten und die Angabe, wer die zuständige Ansprechperson ist, ausreichend sind, und die Telefonnummern für diesen Fall nicht notwendig sind.
Repräsentationelle Datenqualität:
- Eindeutige Auslegbarkeit: Daten sind dann eindeutig auslegbar, wenn sie von allen, die damit arbeiten, in gleicher Art und Weise begriffen werden.
- Verständlichkeit: Ihre Daten sind dann verständlich, wenn sie von den Datennutzer*innen verstanden und für ihre Zwecke eingesetzt werden können. Für unser Ziel, eine Kundendatenbank anzulegen, bedeutet das, dass die aufgeführten Ansprechpersonen mit Vor- und Nachnamen aufgeführt werden und nicht mit Beschreibungen wie „die Frau im dritten Stock mit den braunen Haaren“.
- Einheitliche Darstellung: Wenn die Daten durchgehend auf die gleiche Art und Weise dargestellt werden, sind sie einheitlich. In unserem Fall bedeutet das, für die Angabe der Postleitzahl z. B. zu entscheiden, ob der Ziffernfolge ein „D-“ vorangestellt wird.
- Übersichtlichkeit: Die Übersichtlichkeit von Daten ist dann gewährleistet, wenn sie in einer gut erfassbaren Art und Weise dargestellt werden. In unserem Beispiel heißt das, für die verschiedenen Angaben verschiedene Spalten einzurichten, sodass die Angaben in einer inhaltlich getrennten und nicht verdichteten Form ausgegeben werden können. Gewünscht ist beispielsweise eine Adressangabe nach dem Muster:
Frau
Iris Müller
Blaue Straße 20
D-34567 Grünstadt
und nicht: FrauIrisMüllerBlaueStraße20D-34567Grünstadt
Zugriffsqualität:
- Bearbeitbarkeit: Dieses Kriterium ist erfüllt, wenn sich Ihre Daten leicht für die jeweiligen Nutzungszwecke abändern lassen. Für unsere Beispieldatenbank ist dies bspw. gegeben, wenn die Namen der zuständigen Ansprechpartner bearbeitet werden können. So können mögliche Änderungen zeitnah umgesetzt werden. Läge die Tabelle bspw. im PDF-Format vor, wäre eine Bearbeitbarkeit nicht gegeben.
- Zugänglichkeit: In unserem Beispielsfall können die betreffenden Personen direkt auf die Daten zugreifen und eine Adresse generieren, und sie müssen nicht irgendwo anrufen, um die Adressdaten genannt zu bekommen.
-
Ein Beispiel – Das Ergebnis
Und so sieht schließlich das Ergebnis aus. Bei genauerem Hinsehen erkennen Sie allerdings, dass im Ergebnis die Datenqualitätsdimensionen nicht fehlerfrei umgesetzt wurden. Finden Sie die Fehler?
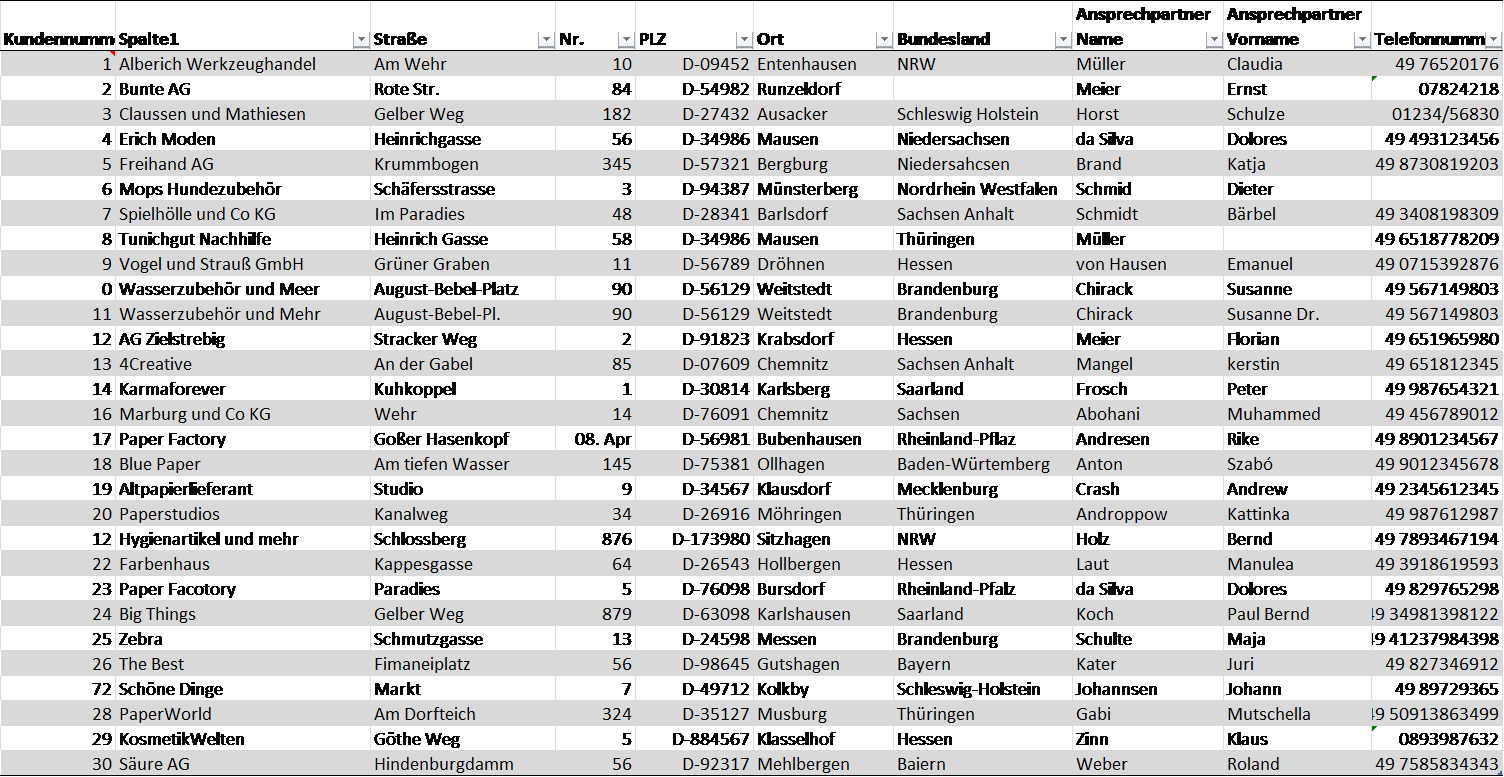
Abb. 6.2: Beispieltabelle zu Datenqualität, Quelle: FOKUS
Zur genauen Fehleranalyse betrachten Sie bitte das folgende Video:
-
-
Hier sind noch einmal die wichtigsten Fakten zum Kapitel zusammengefasst.
-
Bearbeitungsdauer: 21 Minuten, 46 Sekunden
Bearbeitungsdauer (ohne Video): 11 Minuten, 53 Sekunden-
7.4 Verzeichnisstruktur
Eine Verzeichnisstruktur (auch Verzeichnisbaum genannt) ist die Anordnung, in der Ordner angelegt werden. Hierarchische Strukturen erleichtern dabei das Auffinden von Daten (siehe Abbildung 7.1).
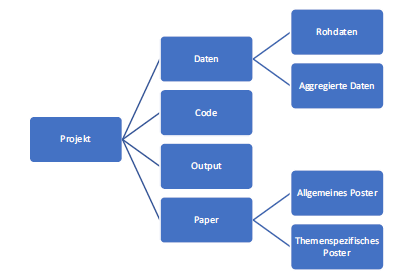
Abb. 7.1: Verzeichnisstruktur bzw. Verzeichnisbaum, Quelle: Biernacka et al. 2018, S. 51
Die Verzeichnisstruktur sollte klar ersichtlich und damit auch für andere Forschende verständlich sein. Hierfür einige Tipps:
- Verwenden Sie trennscharfe Bezeichnungen für Ihre Ordner
- Vermeiden Sie gleiche Bezeichnungen/Namen für Unterordner innerhalb eines Asts im Verzeichnisbaum
- Achten Sie auf ein ausgewogenes Verhältnis zwischen Breite und Tiefe der Struktur. Vermeiden Sie es sowohl viele, thematisch unterschiedliche Dateien in einem Ordner abzulegen, als auch unnötig viele Unterordner in einem Verzeichnis zu erstellen
- Die Voranstellung von Unterstrichen (“_”) oder Zahlen (01, 02, 03 usw.) bei der Benennung von Ordnern, kann bei der Strukturierung helfen
Zur Dokumentation aller Benennungskonventionen und Ablagestrukturen ist es zudem hilfreich, eine Text-Datei anzulegen, welche alle notwendigen Informationen enthält, um den Inhalt des Ordners nachvollziehen zu können. Diese sollte immer auf der obersten Ebene und im Format .txt gespeichert werden, um die Lesbarkeit ohne spezielles Programm zu gewährleisten.
-
7.5 Dateibenennung
Nicht nur die Speicherstruktur, sondern auch die Benennung von Daten und Dateien sollte logisch nachvollziehbar sein. Dazu bieten Ihnen die folgenden Hinweise zu Dateinamen und Schreibweisen eine Orientierung.
Dateiname:
Der Dateiname sollte objektiv und intuitiv sowie personenunabhängig nachvollziehbar sein. Die Benennung und die Kennzeichnung können nach den folgenden drei Kriterien erfolgen:
- System – wichtig für den späteren Zugriff und Abruf der Daten ist die Berücksichtigung des Systems, unter dem die Datei gespeichert wird.
- Kontext – der Dateiname beinhaltet inhaltsspezifische oder deskriptive Informationen, damit unabhängig vom Speicherort klar bleibt, zu welchem Kontext die Datei gehört, z. B. „Zeitplan.pdf“ oder „ZeitplanProjektname.pdf“.
- Konsistenz – wählen Sie die Namenskonvention vorab, um sicher zu stellen, dass sie systematisch befolgt werden kann und die gleichen Informationen (wie z. B. Datum und Zeit) in derselben Reihenfolge beinhaltet (z. B. JJJJ-MM-TT). Dateinamen sollten so lang wie nötig und so kurz wie möglich sein, um übersichtlich zu bleiben und unter jedem Betriebssystem lesbar zu sein. Für eine einheitliche Namensgebung kann man auf die folgenden Namensbestandteile zurückgreifen:
- Inhalt
- Ersteller
- Erstellungsdatum
- Bearbeitungsdatum
- Bezeichnung der Arbeitsgruppe
- Publikationsdatum
- Projektnummer
- Versionsnummer
Schreibweise:
- Sonderzeichen (wie { } [ ] < >
* % # ‘ ; “ , : ? ! & @ $ ~), Leerzeichen und Punkte sollten vermieden werden, da sie unter verschiedenen Systemen unterschiedlich interpretiert werden und dies zu Fehlern führen kann. Verzichten Sie auch auf Umlaute (ä ö ü). Bei den meisten Betriebssystemen kann man Leerzeichen mit Unterstrichen ersetzen oder den Anfangsbuchstaben von Wörtern großschreiben. Die Schreibweise mit Großbuchstaben wird in der Fachsprache auch CamelCase, in Anlehnung an die Höcker eines Kamels, genannt (siehe Abbildung 7.2). Die Schreibweise mit Unterstrichen nennt sich Snake_Case (siehe Abbildung 7.3).
- Um eine chronologische Sortierung zu ermöglichen, empfiehlt es sich, den Namen mit Datumsangabe zu beginnen, zum Beispiel JJMMTTName oder JJJJ-MM-TT_Name:
- 181123CamelCase.txt
- 2018-11-30_snake_case.txt
- Weitere Beispiele für einheitliche Namensgebung:
- 2016-05-12_Klimamessung1_original.jpg
- 2016-05-22_Klimamessung1_MHU_Ausschnitt.jpg
- 2016-05-23_Klimamessung1_MHU_Ausschnitt_bearbeitet_Farbe.jpg
- Automatisch generierte Namen (z. B. von der Digitalkamera) sollten vermieden werden, da sie zu Konflikten durch Wiederholung führen können. Lassen Sie bei der Entscheidung der Namenskonvention die Skalierbarkeit nicht außer Acht: z. B. bei der Wahl einer zweistelligen Dateinummer beschränkt man die Daten auf 00-99 Dateien.
- Nicht nur bei größeren Projekten, sondern auch bei kleineren Forschungsvorhaben, ist es lohnenswert, die gewählten Namenskonventionen schriftlich festzuhalten. Erläutern Sie insbesondere gewählte Abkürzungen in einem Datenmanagementplan oder einer Readme-Datei. Eine Rekonstruktion dieser Konventionen ist nach Jahren oft nur schwer möglich.
- Falls Sie eine ID (siehe auch Kapitel 4) oder Studiennummer haben, sollten Sie diese beifügen, um die Daten zweifelsfrei zu einer Studie und einem Forschenden zuordnen zu können (insbesondere, wenn mehrere Forschende an einem Projekt arbeiten).
- Vermerken Sie durch Kürzel, um welchen Datentyp es sich handelt; z. B. Fragebogen, Experiment, Exzerpt, Audiodatei, etc.


Abb. 7.2: Visualisierung camelCase
(Quelle: Lea Dietz)Abb. 7.3: Visualisierung snake_case
(Quelle: Lea Dietz)
Umbenennung:
Für die Umbenennung bestehender Dateinamen gibt es in Windows mehrere Alternativen. Mittels Rechtsklick und Auswahl des Kontextpunktes ist ein einfaches Umbenennen möglich. Weiterhin kann nach Markieren der jeweiligen Datei die Taste “F2” auf der Tastatur genutzt werden.
Möchten Sie mehrere Dateien gleichzeitig nach bestimmten Konventionen umbenennen, benötigen Sie dafür eine geeignete Software. Diese existiert für die meisten Betriebssysteme.
- Windows:
- Mac:
- Linux:
- GNOME Commander
- GPRename
- Unix: Unter Unix kann das Kommando “rename” hilfreich sein, um mit regulären Ausdrücken Dateien aufzufinden und umzubenennen.
In diesem Video von Christian Krippes (2018) sind die wichtigsten Grundregeln für eine strukturierte und übersichtliche Dateibenennung noch einmal kurz zusammengefasst.

-
7.7 Datenbanken und Datenbanksysteme
Geeignete Konventionen zur Benennung und Ablage von Dateien sind bereits ein wichtiger Baustein für eine effiziente Datenorganisation. Arbeiten Sie jedoch mit besonders vielen Dateien oder haben Sie besondere Anforderungen an die Strukturierung Ihrer Daten, insb. hinsichtlich der Durchsuchbarkeit, kann die Verwendung von Datenbanksystemen hilfreich sein. Hierbei werden nicht nur die Dateien selbst sinnvoll strukturiert, sondern in einer Datenbank verzeichnet und mit Metadaten (siehe Kapitel 4) versehen. Die Metadaten ermöglichen dabei gezielte Filter- und Suchfunktionen. So könnten bspw. in einer Bilddatenbank schnell und komfortabel alle Bilder angezeigt werden, die von einer bestimmten Agentur an einem bestimmten Ort zu einer bestimmten Zeit gemacht wurden. In Abbildung 7.4 werden die Grundbegriffe der Datenorganisation und ihre hierarchische Beziehung zueinander noch einmal veranschaulicht.
Abb. 7.4: Grundbegriffe der Datenorganisation, Quelle: De Lange 2006, S. 328
Auf der untersten Ebene der Datenorganisation befinden sich Datenfelder. Diese enthalten Attributwerte, nach denen sie logisch zusammengehörend Datensegmenten (Datengruppen) zugeordnet werden können. Mehrere Datensegmente bauen einen Datensatz auf. Logisch zusammengehörende Datensätze bilden dann eine Datei, während zusammengehörige Dateien Dateisysteme bzw. Datenbanken bilden.
Datenbanken reichen für viele Anforderungen der Nutzer allerdings nicht zur Datenorganisation aus; z. B. müssen einige Daten mehrfach an verschiedenen Orten gespeichert werden, um sie für unterschiedliche Anwendungen nutzen zu können. Zudem kann Datenschutz über die Vergabe von Zugriffsrechten nur schwer gewährleistet werden. Daher werden Datenbanksysteme benötigt.
„Ein Datenbanksystem (DBS) besteht aus dem Datenbankverwaltungssystem oder Datenbankmanagementsystem (DBMS) und mehreren Datenbanken (DB, auch Datenbasen)“ (De Lange 2006: 332). Doch was sind Datenbanken und Datenbankmanagementsysteme? Eine Datenbank besteht aus „mehreren, untereinander verknüpften Daten“ (Herrmann 2018: 5), womit sie eine Datensammlung ist, deren Daten „in einer logischen Beziehung stehen“ (Herrmann 2018: 5). Die Datenbank wird vom Datenbankmanagementsystem verwaltet; letzteres ist also eine Software.
Somit bieten Datenbanksysteme den Nutzern effizienten und gebündelten Zugang auf Daten und sollen die folgenden Anforderungen erfüllen (De Lange, 2006, S. 333):
- Auswertbarkeit der Daten nach beliebigen Merkmalen
- Einfache Abfragemöglichkeiten und Auswertung, schnelle Bereitstellung der Daten
- Zuweisung verschiedener Nutzungsrechte an die einzelnen Benutzer
- Daten und Anwenderprogramme sind unabhängig voneinander, sodass der Anwender nur die logischen Datenstrukturen kennen muss, während das DBS die organisatorische Verwaltung übernimmt
- Keine Datendopplung und Datenintegrität
- Datensicherheit bei Hardwareausfällen und Fehlern der Anwenderprogramme
- Datenschutz gegen unbefugten Zugriff
- Flexibilität hinsichtlich neuer Anforderungen
- Zulassung von Mehrbenutzerzugriffen
- Einhaltung einheitlicher Standards
Zu den geläufigsten Datenbankmanagementsystem gehören unter anderen Oracle, MySQL, Microsoft Access und SAP HANA.
-
-
Hier sind noch einmal die wichtigsten Fakten zum Kapitel zusammengefasst.
-
Bearbeitungsdauer: 18 Minuten, 3 Sekunden
-
8.2 Speichermedien und -orte: Vor- und Nachteile
Wie bereits in Kapitel 7 angemerkt, sollten Forschungsdaten regelmäßig gespeichert sowie die Fortschritte und Änderungen möglichst über Versionen gekennzeichnet und gut dokumentiert werden.
Das Speichern sollte auf unterschiedlichen Medien erfolgen. Bei Ihrer Entscheidung für ein Medium sollten Sie nach Ludwig/Enke (2013, S. 33) die folgenden Faktoren beachten:
- Größe der Datensätze
- Anzahl der Datensätze
- Häufigkeit des Datenzugriffs
Speichermedien haben verschiedene Eigenschaften, wodurch es je nach Medium teils erhebliche Unterschiede beim Schutz vor Datenverlust und vor unbefugtem Zugriff gibt. Im Folgenden bekommen Sie einen kompakten Überblick über die Eigenschaften, Vorteile und Risiken der häufigsten Speichermedien und -orte:
Eigener PC
Vorteile
Nachteile
-
Eigenverantwortlichkeit für Sicherheit und Backup
-
eigene Kontrolle
-
alles, was mit dem PC geschieht, geschieht mit dem Backup
-
evtl. fehlende Ressourcen und Know-how zum Konfigurieren und Überprüfen der Qualität der Sicherungskopien
-
Einzellösungen aufwendig, kostspielig und ineffizient bezogen auf eine Arbeitsgruppe
Mobiles Speichermedium (z. B. CD, DVD, USB-Stick, externe Festplatte)
Vorteile
Nachteile
-
leicht zu transportieren
-
können im verschließbaren Schrank oder Safe aufbewahrt werden
-
besonders leicht zu verlieren und können einfach entwendet werden, daher äußerst unsicher
-
Inhalte sind bei Verlust ungeschützt, wenn sie nicht zuvor verschlüsselt wurden
-
anfällig hinsichtlich Temperatur, Luftqualität und Feuchtigkeit
-
externe Festplatten besonders stoß- und verschleißanfällig
Institutionelle Speicherorte (z. B. Server Ihrer Universität)
Vorteile
Nachteile
-
Backup der Daten ist sichergestellt
-
Professionelle Durchführung und Wartung
-
Speicherung entsprechend den Datenschutzrichtlinien der Institution
-
Datenschutz über Zugriffsrechte geregelt
-
Für mobiles Arbeiten weltweit nutzbar
-
Geschwindigkeit vom Netzwerk abhängig
-
Zugriff auf Backups evtl. verzögert durch Dienstweg
-
ggf. unklar, welche Sicherheitskriterien angewendet und Sicherheitsstrategien eingesetzt werden
-
ggf. mit höheren Kosten verbunden
Externe Speicherorte (z. B. Cloud-Dienste externer Unternehmen)
Vorteile
Nachteile
-
einfach zu nutzen und zu verwalten
-
werden professionell gewartet
-
für mobiles Arbeiten weltweit nutzbar
-
je nach Anbieter kann die Verbindung auch unsicher sein
-
abhängig vom Zugang zum Internet
-
Upload und Download kann lange dauern
-
Zugriff auf Backups evtl. verzögert
-
unklar, welche Sicherheitskriterien angewendet und Sicherheitsstrategien eingesetzt werden und ob diese den Vorgaben für sensible Daten entsprechen
-
viele Institutionen haben für die Nutzung solcher Dienste spezielle Regelungen erlassen
Tab. 8.1: Vor- und Nachteile verschiedener Speichermedien und -orteDie Verwendung von kostenlosen Cloud-Speicherdiensten, wie beispielsweise Dropbox, OneDrive oder Google Drive, ist zu vermeiden. Da der Serverstandort für diese Anbieter in Amerika liegt, gilt für die Daten und Ihre Privatsphäre das dortige Recht, was vor allem mit Blick auf den USA PATRIOT Act von 2001 kritisch gesehen werden muss, da die Daten nicht vor allen ungewünschten Zugriffen durch Dritte geschützt sind und nicht kontrolliert werden kann, was mit den Daten geschieht.
Die Frankfurt UAS bietet als sichere Alternative allen Hochschulmitgliedern und -angehörigen (mit Ausnahme der Studierenden) mit einem gültigen CIT-Account die Nutzung von Nextcloud an.

Nextcloud ist eine Open-Source-Lösung für das Speichern von Dateien (Filehosting). Funktional ähnelt es Dropbox, Google Drive oder anderen Filehosting-Diensten. Jegliche Dateien bleiben jedoch auf den Servern der Hochschule gespeichert. Allen Nutzerinnen und Nutzern stehen fünf Gigabyte für die Dateiablage zur Verfügung. Die Dateien können über einen Client mit dem lokalen Speicher synchronisiert oder unter nextcloud.frankfurt-university.de abgerufen werden. Weitere Informationen erhalten Sie in der Nextcloud Knowledge Base auf Confluence.
Auch nicht-digitale Medien dürfen nicht vergessen werden. Viele Daten befinden sich auf handschriftlichen Notizen oder gedruckten, papier-basierten Materialien (z. B. Fotos). Hier tragen insbesondere Sonneneinstrahlung, Säure oder Fingerabdrücke zum schnellen Verschleiß bei. Wenn Daten auf Papier gelagert werden, sollten Sie nach Corti et al. (2014, S. 87)…
- …säurefreies Papier nutzen.
- …Ordner und Boxen nutzen.
- …rostfreie Büroklammern verwenden.
Außerdem sollten Sie die Daten zusätzlich einscannen, sodass sie auch in einem digitalen Format vorliegen. Im Bedarfsfall können diese digitalen Daten dann beispielsweise wieder über einen Druck in ein materielles Format gebracht werden. Zur Übertragung in ein digitales Format bietet sich insbesondere das PDF/A-Format an. Allerdings können nicht alle Dokumente problemlos in das PDF/A-Format überführt werden. Es gibt jedoch kostenlose Tools, die die PDF/A-Konformität überprüfen können. Sollte das Format für ihre Daten nicht in Frage kommen, scannen Sie es einfach im PDF-Format.
Weiterhin zu beachten ist, dass mindestens zwei Personen Zugang zu den Daten haben sollten, um auch im Krankheitsfall oder bei Abwesenheit die Verfügbarkeit der Daten zu gewährleisten.
-
8.5 Backup
Gegenteilig zu diesen Maßnahmen, mit denen Sie Daten endgültig und sicher löschen, können Daten auch unbeabsichtigt verloren gehen. Um Daten nicht aus Versehen zu löschen oder durch Unfälle zu zerstören, müssen Sie regelmäßig Backups machen.
Das Erstellen einer Sicherungskopie von Daten sollte immer auf einem Speichermedium erfolgen, welches von der üblicherweise genutzten Infrastruktur getrennt ist. Ein Backup sollte planvoll und strukturiert vorgenommen werden. Somit sollten die Daten möglichst regelmäßig gesichert werden, um im Bedarfsfall eine Datenrekonstruktion möglichst einfach durchführen zu können. Bevor Sie jedoch ein Backup machen, sollten Sie organisatorische Fragen klären:
- Gibt es bereits laufende Backup-Pläne? Wie sehen diese aus?
- Wovon soll wie oft ein Backup gemacht werden?
- Wo sollen die Backups gespeichert werden?
- Wie sollen die Backups gespeichert werden? (z. B. Beschriftung, Sortierung, Dateiformat)
- Welche Backup-Tools können helfen?
- Wie ist der Umgang mit sensiblen Daten?
Es empfiehlt sich, eine automatisierte Routine zu verwenden. Partielle Daten, an denen derzeit gearbeitet wird, sollten möglichst täglich gesichert werden. Zudem ist es ratsam, diese nicht täglich zu überschreiben, da man so gegebenenfalls Fehler rekonstruieren kann oder auch Änderungen, die fälschlicherweise durchgeführt wurden, rückgängig machen kann. Zusätzlich sollte ein wöchentliches Gesamtbackup erstellt werden. Der Grundsatz des 3-2-1 Backups ist hierbei nützlich (siehe Abbildung 8.1).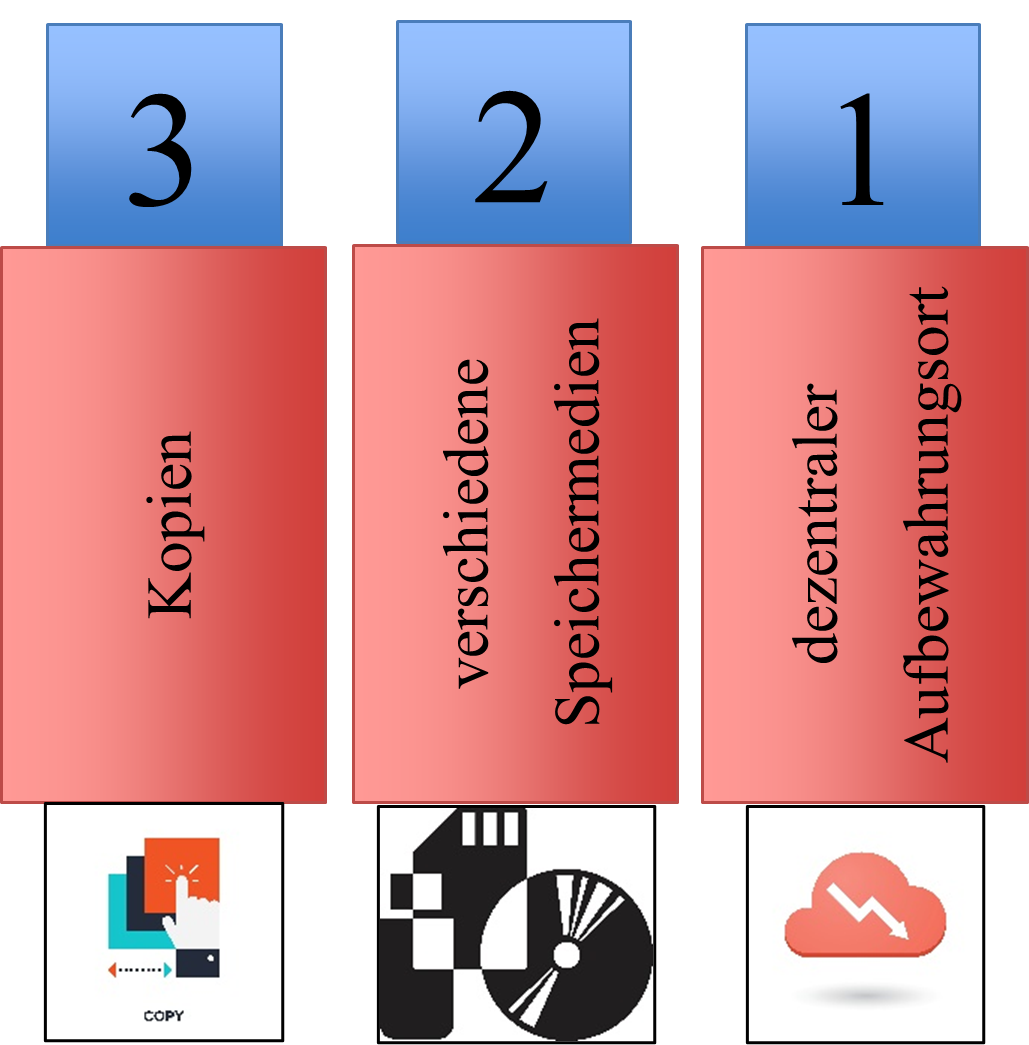 Abb. 8.1: Die 3-2-1 Backup-Regel (CC-BY SA, Andre Pietsch)
Abb. 8.1: Die 3-2-1 Backup-Regel (CC-BY SA, Andre Pietsch)Unter einem dezentralen Aufbewahrungsort versteht man die in Tabelle 8.1 genannten institutionellen sowie externen Speicherorte. Einen institutionellen, dezentralen Aufbewahrungsort sollten Sie hierbei immer bevorzugen.
Das Backup bzw. die daraus entstehende Datenwiederherstellung sollten zu Beginn sowie in regelmäßigen Abständen überprüft werden. Die meisten Institutionen bieten eine automatische Lösung an, bei der alle Daten ausschließlich auf von den Hochschulrechenzentren der Universitäten bereitgestellten gesicherten Laufwerken abgelegt werden. Durch diese Professionalisierung wird erreicht, dass die Sicherungen nicht vergessen werden können und die Konfiguration des Backup-Systems nicht einzeln zu erfolgen braucht.
Zusätzlich können Sie Ihre Backups nach der Erstellung über Prüfsummen kontrollieren. Dafür müssen Sie allerdings nach Erstellung der Backupdateien für diese Dateien MD5- oder SHA1-Prüfsummen erstellen lassen. Dabei hilft Ihnen das von Microsoft zur Verfügung gestellte Dienstprogramm „File Checksum Integrity Verifier“, kurz FCIV. Eine Anleitung, wie Sie dieses verwenden, finden Sie hier. Wenn die Prüfsummen sowohl Ihrer Originaldaten als auch des Backups identisch sind, sind es auch die Daten. So können Sie die Integrität Ihrer Daten prüfen und stellen fest, ob eventuell Fehler beim Kopieren der Daten aufgetreten sind. Sollten Sie übrigens auch Softwarecode veröffentlichen, ist es im Programmierbereich üblich, die Checksumme der Installationsdatei („*.exe“) beim Download mit anzugeben, damit interessierte Nutzer vorher überprüfen können, ob es sich um eine originale Installationsdatei handelt und nicht womöglich um eine mit Viren infizierte Datei. -
-
Hier sind noch einmal die wichtigsten Fakten zum Kapitel zusammengefasst.
-
Disclaimer: Keine rechtverbindlichen Informationen! Für eine dezidierte Rechtsberatung zu Ihrer Forschung, wenden Sie sich bitte an das Justiziariat oder den Datenschutzbeauftragten der Frankfurt UAS.
Bearbeitungsdauer: 67 Minuten, 10 Sekunden
Bearbeitungsdauer (ohne Video): 20 Minuten, 36 Sekunden-
9.1 Einführung & Lernziele
Rechtliche Fragen im Umgang mit Forschungsdaten stellen sich in jeder Phase des Forschungsdatenlebenszyklus. Einen ersten Überblick, welche rechtlichen Aspekte im Umgang mit Daten in welcher Phase jeweils zu beachten sind, gibt Abbildung 9.1.
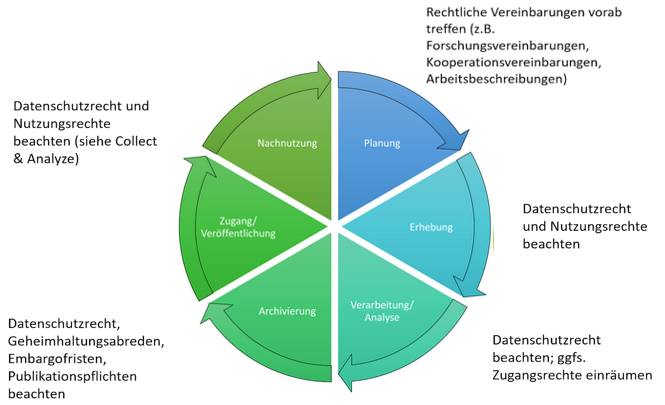
Bearbeitung angelehnt an: Paul Baumann/Philipp Krahn, Rechtliche Rahmenbedingungen des FDM - Grundlagen und Praxisbeispiele, Dresden 2020, Folie 4
Abb. 9.1: Rechtliche Aspekte des Forschungsdatenmanagements im Forschungsdatenlebenszyklus
Nicht für alle rechtlichen Details im Umgang mit Ihren Forschungsdaten müssen Sie selbst Lösungen finden. Über einige rechtliche Konstellationen sollten Sie aber zumindest in Grundzügen selbst Bescheid wissen, wenn Sie im Sinne guter wissenschaftlicher Praxis und Forschungsethik arbeiten wollen.
Nach Abschluss dieses Kapitels können Sie...
- ...die wichtigsten Rechtsgebiete im Umgang mit Forschungsdaten benennen
- ...konkrete Schritte zur rechtskonformen Umsetzung Ihres Forschungsvorhaben unternehmen
- ...entscheiden ob und wie Sie Ihre Daten veröffentlichen können
- ...sich bei Fragen an die richtige Stelle wenden
Bei komplizierten rechtlichen Fragen können Sie sich bspw. an das Justiziariat und/oder den Datenschutzbeauftragten der Frankfurt UAS wenden. Darüber hinaus hilft Ihnen auch Ihr Referent für Forschungsdatenmanagement gerne weiter. -
9.3 Datenschutz
Bei der Erhebung, Speicherung, Verarbeitung und Weitergabe von Forschungsdaten mit Personenbezug sind Datenschutzrechte beachten. Wenn Sie als Wissenschaftler*in an einer hessischen Hochschule mit entsprechenden Daten arbeiten, empfiehlt es sich die Grundzüge insbesondere der folgenden Gesetzestexte zu kennen:
- Datenschutz-Grundverordnung der Europäischen Union (DS-GVO)
- Bundesdatenschutzgesetz (BDSG)
- Hessisches Datenschutz- und Informationsfreiheitsgesetz (HDSIG)
Im folgenden Video werden die für die wissenschaftliche Forschung besonders relevanten Gesetze zum Datenschutz kurz vorgestellt und ihre Beziehung zueinander erläutert:
Quelle: "Datenschutz in der Forschung", Prof. Dr. Iris Kirchner-Freis, MLS Legal
Daten ohne Personenbezug bzw. anonymisierte Informationen fallen dagegen nicht unter das Datenschutzrecht und können grundsätzlich unter Berücksichtigung sonstiger Rechte (z. B. Urheberrechte) frei verarbeitet werden.
Worin genau sich Daten mit Personenbezug von anderen (anonymen) Forschungsdaten unterscheiden, wird im folgenden Abschnitt noch genau erklärt. Im Zweifelsfall sollten Sie zur Vermeidung von Haftungsrisiken von einem Personenbezug ausgehen.
9.3.1 Personenbezogene Daten und besondere Kategorien personenbezogener Daten
Personenbezogene Daten sind gemäß Art. 4 Abs. 1 DSGVO alle Informationen, die sich auf eine identifizierte oder identifizierbare lebende Person beziehen. Beispiele für personenbezogene Forschungsdaten sind z. B. Umfragedaten in den Sozialwissenschaften oder Gesundheitsdaten in der medizinischen Forschung.
Als identifizierbar wird eine Person angesehen, die direkt oder indirekt mittels Zuordnung identifiziert werden kann:
- insbesondere zu einer Kennung wie einem Namen, zu einer Kennnummer, zu Standortdaten, zu einer Online‐Kennung oder
- zu einem oder mehreren besonderen Merkmalen, die Ausdruck der physischen, physiologischen, genetischen, psychischen, wirtschaftlichen, kulturellen oder sozialen Identität dieser natürlichen Person sind.
In der Rechtsprechung sind zuletzt insbesondere folgende Fälle entschieden worden:
Beispiele
- Bildnisse, Film- und Tonaufnahmen, wenn ein Personenbezug besteht
- IP‐Adressen
- schriftliche Antworten eines Prüflings in einer berufsbezogenen Prüfung
- Anmerkungen der Prüfenden zur Bewertung dieser Antworten
Bei der Prüfung, ob eine Person identifizierbar ist, sind nach der DSGVO alle Mittel zu berücksichtigen, die von dem Verantwortlichen oder einer anderen Person unter normalen Umständen (hinsichtlich Kosten‐ und Zeitaufwand) wahrscheinlich genutzt werden, um die Person zu identifizieren (Erwägungsgrund 26 DSGVO).
Quelle: "Datenschutz in der Forschung", Prof. Dr. Iris Kirchner-Freis, MLS Legal
Darüber hinaus gibt es in der Rechtsprechung Datenkategorien, die als besonders sensibel angesehen werden. Hierzu zählen bspw. Daten über den Gesundheitszustand einer Person, deren sexuelle Orientierung sowie politische oder religiöse Ansichten. Eine Auflistung dieser besondere Kategorien personenbezogener Daten findet sich in Art. 9 DSGVO.
Diese Daten unterliegen einem besonderen Schutz und besonderen Sorgfaltspflichten bei der Verarbeitung. Dies bedeutet bspw., dass Teilnehmer*innen wissenschaftlicher Studien der Verarbeitung dieser besonderen Kategorien personenbezogener Daten vor der Datenerhebung ausdrücklich zustimmen müssen. Weitere Aspekte werden im folgenden Video erläutert:
Quelle: "Datenschutz in der Forschung", Prof. Dr. Iris Kirchner-Freis, MLS Legal
Bei der Verarbeitung personenbezogener Daten sind die sog. allgemeinen Datenverarbeitungsgrundsätze (Art. 5 DSGVO) zu beachten:
- Personenbezogene Forschungsdaten dürfen nur erhoben werden, wenn sie zum Erreichen des Forschungszweckes erforderlich sind.
- Die Erhebung und Verarbeitung muss gegenüber den betroffenen Personen transparent und mit der gebotenen Redlichkeit geschehen.
- Die Betroffenen müssen jederzeit die Möglichkeit haben, die Verarbeitung ihrer persönlichen Daten nachvollziehen zu können, und dürfen nicht durch falsche und unterbliebene Informationen in die Irre geführt werden.
- Der Schutz der Privatsphäre durch Schutz der personenbezogenen Daten sollte bei allen Überlegungen zur Erhebung und Verarbeitung im Mittelpunkt stehen.
- Die Daten müssen zudem die Lebensumstände der betreffenden Person korrekt wiedergeben, dürfen sie also nicht verfälschen.
- Sie sind im Rahmen des Zumutbaren vor Missbrauch (z. B. Entnahme, Veränderung, Beschädigung) technisch und organisatorisch zu schützen.
9.3.2 Informierte Einwilligung und gesetzliche Erlaubnisnormen
Grundsätzlich dürfen personenbezogene Forschungsdaten nur mit einer informierten Einwilligung der Betroffenen oder einer gesetzlichen Erlaubnisnorm erhoben und verarbeitet werden (sog. Grundsatz des Verbots mit Erlaubnisvorbehalt).
Für die informierte Einwilligung lassen sich gemäß Erwägungsgrund 32 S.2 DSGVO folgende Vorgaben festhalten:
- Die Einwilligung muss aus freien Stücken (d. h. ohne physische oder psychische Beeinflussung) erfolgen
- Insbesondere bei der Verarbeitung sensibler personenbezogener Daten (gemäß Art. 9 oder 10 DSGVO) empfiehlt sich eine schriftliche Fixierung der Einwilligung
- Die Einwilligenden müssen durch entsprechende Vorabinformationen genau nachvollziehen können, welche ihrer persönlichen Daten wie, für was, von wem und wie lange verwendet werden sollen. D. h. die Personen sollen in die Lage versetzt werden, die Konsequenzen der eigenen Einwilligung genau einschätzen zu können.
Demgegenüber greifen gesetzliche Erlaubnistatbestände ohne Zutun des Betroffenen. Besondere Bedeutung kommt den in § 27 BDSG, aber auch in vielen Landesdatenschutzgesetzen (z. B. § 13 LDSG-BW, § 17 DSG-NRW, § 13 NDSG) enthaltenen Ausnahmen für wissenschaftliche Forschungszwecke zu.
Danach ist die Verarbeitung von personenbezogenen Daten erlaubt, wenn die mit dem Forschungsvorhaben verfolgten Interessen diejenigen der betroffenen Personen überwiegen (vgl. forschungsdaten.info). Da dies jedoch nur selten zutrifft, sollten Sie im Zweifelsfall immer eine Einwilligung einzuholen.
Die Einwilligung bedarf keiner besonderen Form. Jedoch muss sie – z. B. bei einer Überprüfung durch die Datenschutzaufsichtsbehörde – nachweisbar sein, so dass eine schriftliche oder elektronische Dokumentation dringend zu empfehlen ist. Die Einwilligungserklärung sollte mindestens folgende Informationen enthalten:
- Verantwortliche*r für die Datenerhebung (Rechtspersönlichkeit), der*die gleichzeitig Adressat*in der Einwilligungserklärung ist;
- Projekttitel;
- Konkrete Informationen über die Art der erhobenen Daten;
- Datenverarbeitungsprozesse, Verantwortliche*r im Sinne des Datenschutzes;
- Hinweis auf Freiwilligkeit, auf Widerrufsrecht, Hinweis auf die Folgen oder die Folgenlosigkeit bei Verweigerung oder Widerruf;
- besonders wichtig: Verwendungszweck(e).
Insbesondere muss der Betroffene muss darauf hingewiesen werden, dass seine Einwilligung völlig freiwillig ist, er sie deshalb auch verweigern und – wenn er sie erteilt – die Einwilligung mit Wirkung für die Zukunft jederzeit widerrufen kann, bisherige Nutzungen aber nicht rückgängig gemacht werden können (Vgl. https://www.forschungsdaten-bildung.de/einwilligung).
Ergänzt werden muss die Einwilligungserklärung um Informationen über die Verarbeitung der Daten. Darunter fallen die Rechtsgrundlagen und Zwecke der Verarbeitung (soweit diese über die Verarbeitung hinausgehen), eine eventuelle Datenübermittlung in Länder außerhalb der EU, die Speicher- bzw. Löschfristen der personenbezogenen Daten und das Beschwerderecht bei einer Datenschutzaufsichtsbehörde (vgl. Watteler/Ebel 2019: 60).
Die Einwilligung kann für den Wissenschaftsbereich auch abstrakt für wissenschaftliche Zwecke gegeben werden, die zum Zeitpunkt der Erhebung nicht bekannt sind (sog. broad consent). Je konkreter die Beschreibung jedoch erfolgt, desto eher wird sich die Reichweite der betreffenden Einwilligung auf Nutzungen erstrecken können, die über die Verwendung des Primärzwecks hinausgehen. Wenn die Veröffentlichung der Daten im Rahmen des FDM beabsichtigt ist, sollte die Einwilligung explizit auch die Speicherung und Veröffentlichung der Daten umfassen. Ein praktikabler Kompromiss zwischen abstraktem und konkretem Broad Consent kann bspw. in einer abgestuften Einwilligung bestehen.

Abb. 9.2: Beispiel einer informierten Einwilligung im “Broad-Consent-Format”, Quelle: Baumann/Krahn 2020
Das folgende Video fasst alle Aspekte zur informierten Einwilligung und zu den gesetzlichen Erlaubnistatbeständen noch einmal zusammen:
Quelle: "Datenschutz in der Forschung", Prof. Dr. Iris Kirchner-Freis, MLS LegalWeiterführende Informationen
Einige Fachdisziplinen bieten Hilfestellungen und Formulierungsbeispiele für schriftlich verfasste informierte Einwilligungen (vgl. z. B. VerbundFDB, RatSWD).
-
Mustererklärung für mündliche oder schriftliche Interviews des Arbeitskreis Deutscher Markt- und Sozialinstitute
-
Formulierungsbeispiele für "informierte Einwilligungen" des VerbundFDB
-
Vorlage für die informierte Einwilligung zur Verarbeitung personenbezogener Daten (Deutsch/Englisch) von Qualiservice
-
Handreichung zur Informierten Einwilligung (Erläuterungen zur Verwendung der QS-Vorlagen)
9.3.3 Mittel zur Entfernung identifizierender Merkmale
Allgemein gilt, dass personenbezogene Forschungsdaten nach der Erhebung, sobald es der Forschungszweck zulässt (spätestens mit Abschluss des Forschungsvorhabens), anonymisiert werden müssen.Anonymisierung
Eine derartige Veränderung der Daten, dass die Einzelangaben über persönliche oder sachliche Verhältnisse nicht mehr (sog. absolute Anonymisierung) oder nur mit einem unverhältnismäßig großen Aufwand an Zeit, Kosten und Arbeitskraft (sog. faktische Anonymisierung) einer bestimmten oder bestimmbaren natürlichen Person zugeordnet werden können.
Der erste Schritt ist dabei die Entfernung direkter Identifikationsmerkmale (Name, Adresse, Telefonnummer usw.). Oftmals reicht dies jedoch nicht aus um einen Personenbezug auszuschließen. In diesem Fall kann die Reduzierung der Informationsgenauigkeit (Aggregierung) ein wirksames Mittel sein, das zudem erlaubt gewisse Informationsteile trotzdem zu behalten.Aggregierung
Zusammenfassung mehrerer gleichartiger Einzelwerte zur Verringerung der Granularität von Informationen. Aus der zusammengefassten Information ist ein Rückschluss auf die Einzelinformationen nicht mehr möglich.
Hierbei werden also detaillierte Einzelinformationen (z. B. Gehalt im letzten Monat) in Klassen gruppiert (z. B. Unter-, Mittel-, Oberschicht). Der Grad der Aggregierung, der nötig ist um einen Personenbezug auszuschließen kann dabei variieren. Er hängt im Wesentlichen davon ab, welche weiteren potenziellen Identifikationsmerkmale in den Daten vorhanden sind oder aus externen Quellen zugespielt werden können.
Beispiel für eine graduelle Aggregierung:
Adresse → Ort → Bundesland → Ost/West → Land → Kontinent
Es ist in jedem Fall sorgfältig zu prüfen, welche der zur Verfügung stehenden Mittel am geeignetsten und verhältnismäßigsten erscheinen, die identifizierenden Merkmale so zu entfernen, dass auch mit etwaigem Zusatzwissen sowie umfangreichen Kapazitäten zur Datenrecherche und ‐aggregation keine oder nur eine sehr eingeschränkte De‐Anonymisierung möglich ist.
Ein Aufschub der Anonymisierung ist nur dann möglich, wenn jene Merkmale, mit deren Hilfe ein Personenbezug hergestellt werden kann, zum Erreichen des Forschungszweckes oder einzelner Forschungsschritte benötigt werden. Dies ist beispielsweise während eines noch laufenden Forschungsprojektes, welches auf biometrische Daten zurückgreift, der Fall.
In diesem Fall müssen die personenbezogenen Merkmale jedoch unmittelbar nach der Erhebung getrennt und sicher gespeichert werden. Dies kann bspw. durch eine Pseudonymisierung der personenbezogenen Forschungsdaten erfolgen.
Pseudonymisierung
Die Trennung der personenbezogenen Merkmale unmittelbar nach der Erhebung von den restlichen Daten, so dass die Daten ohne Hinzuziehung zusätzlicher Informationen nicht mehr einer spezifischen Person zugeordnet werden können.
Ein Beispiel ist die Verwendung einer Schlüsseltabelle, die den Klarnamen von Personen entsprechende ID-Codes zuweist. So kann der Personenbezug nur hergestellt werden, wenn man im Besitz der Schlüsseltabelle ist. Diese kann ggf. auch von einem unabhängigen Treuhänder verwahrt werden.
Die auf diese Weise verarbeiteten Daten weisen aber bis zur Löschung der separat zu speichernden personenbezogenen Merkmale weiterhin einen Personenbezug auf und unterliegen damit den datenschutzrechtlichen Vorgaben.
Quelle: "Datenschutz in der Forschung", Prof. Dr. Iris Kirchner-Freis, MLS Legal -
9.4 Entscheidungsbefugnis
Neben dem Datenschutz ist eine weitere wichtige Frage, wer über den Umgang mit den Forschungsdaten, insbesondere ihre Veröffentlichung, entscheiden kann. In der Regel kann diejenige Person, der die Forschungsdaten “zugeordnet” sind, auch über deren Umgang wie z. B. deren Veröffentlichung entscheiden. Eine solche “Zuordnung” kann sich etwa aus dem Urheberrecht, dem Dienstvertragsrecht oder dem Patentrecht ergeben.
9.4.1 Urheberrechte und Leistungsschutzrechte
In der Regel kann die urheberrechtliche Schutzfähigkeit einzelner Forschungsdaten nur im Einzelfall und selbst dann nicht mit hinreichender Rechtssicherheit beurteilt werden. Gleichwohl lassen sich verschiedenen Fallgruppen von Forschungsdaten nach der konkrete Art der verkörperten Informationen und vor allem deren Gewinnung unterscheiden:
-
Qualitative Forschungsdaten sind z. B. Sprachwerke wie qualitative Interviews oder längere Texte. Sie können grundsätzlich urheberrechtlich geschützte Formulierungen, Strukturen und Gedankenführungen enthalten. Ein urheberrechtlicher Schutz ist ausgeschlossen, wenn Formulierungen, Struktur und Gedankenführung im Wesentlichen durch fachliche Gepflogenheiten vorgegeben sind.
-
Wissenschaftliche Darstellungen, wie Zeichnungen, Pläne, Karten, Skizzen und Tabellen, können einem urheberrechtlichen Schutz unterliegen, wenn die Darstellung nicht durch Sachzwänge oder fachwissenschaftliche Gepflogenheiten vorgegeben ist, sondern ein Gestaltungsspielraum der Wissenschaftler*innen besteht.
-
Unter den gleichen Voraussetzungen sind auch Fotografien und andere Lichtbilder urheberrechtlich geschützt. Hierunter fallen neben Fotografien auch Aufnahmen aus bildgebenden Verfahren, wie z. B. Röntgen-, Kernspin und Computertomografiebilder sowie Fotografien und Einzelbilder aus Filmen.
-
Quantitative Daten sind z. B. Messergebnisse oder statistische Daten. Im Rahmen standardisierter Erhebungen wird in den meisten Fällen kein urheberrechtlicher Schutz bestehen.
-
Bei (quantitativen) Forschungsdaten, deren Anordnung und Zusammenstellung individualitätsbegründend wirkt, handelt es sich um ein sog. Datenbankwerk (§ 4 UrhG). Nur dessen Struktur und nicht die Informationen als solche unterliegen einem urheberrechtlichen Schutz.
-
Metadaten sind meist relativ kurze, rein beschreibende Darstellungen. Sie sind meist nicht urheberrechtlich geschützt. Eine Schutzfähigkeit kommt grundsätzlich nur in den seltenen Fällen in Betracht, in denen Sie z. B. längere Textabschnitte oder Lichtbilder enthalten.
Fotografien und andere Lichtbilder können zudem durch ein Leistungsschutzrecht nach § 72 UrhG geschützt sein. Die folgende Abbildung von Brettschneider (2020) unternimmt den Versuch einer Pauschalisierung der Schutzfähigkeit von Forschungsdaten als urheberrechtliche Werke:
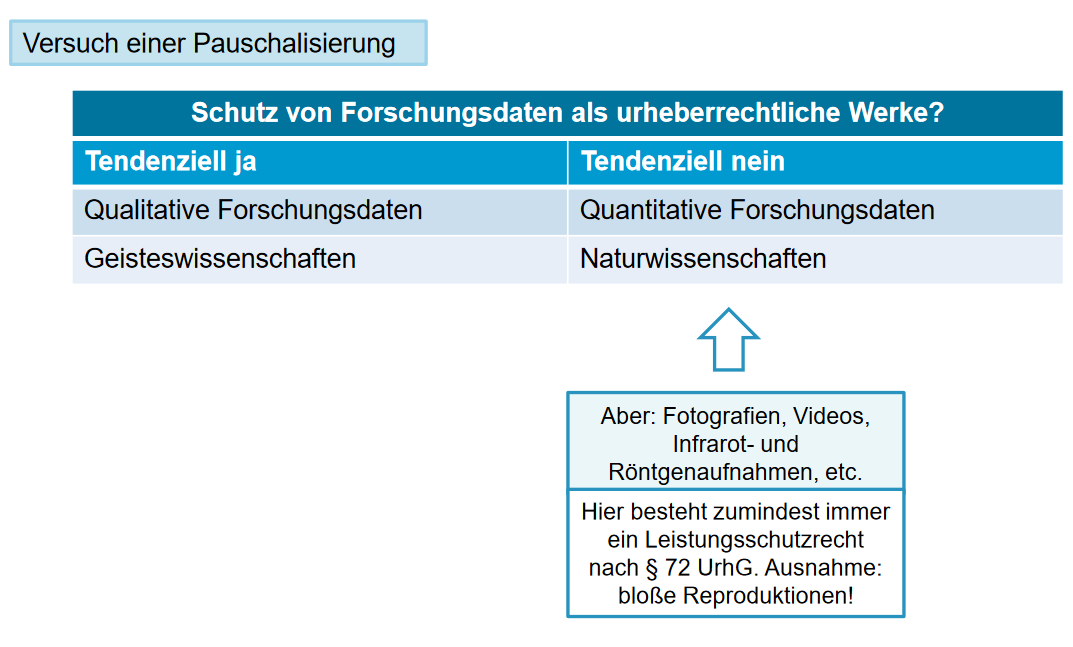
Zusammenstellungen von Forschungsdaten im Rahmen einer Datenbank können - außer, dass sie als Datenbankwerk urheberrechtlich geschützt sein können - zudem durch das Datenbankherstellerrecht (§87a UrhG) geschützt werden. Dieses Leistungsschutzrecht erfordert einen wesentlichen Investitionsaufwand hinsichtlich der Sammlung, Ordnung und Zugänglichmachung der Forschungsdaten.
Inhaber*in der Datenbankherstellerrechte ist regelmäßig die Person, die die wesentlichen Investitionen erbringt, z. B. die Vergütung der Forschenden zahlt und das wirtschaftliche Risiko trägt. Gemeinhin ist dies ebenfalls die anstellende Hochschule oder Forschungseinrichtung. Im Einzelfall kommt auch eine Inhaberschaft der Drittmittel- oder Auftraggebenden in Frage.
Bei nicht geschützten Forschungsdaten (z. B. Messergebnissen) ist rechtlich weitgehend ungeklärt, wem im konkreten Einzelfall die Entscheidungsbefugnis über die Daten obliegt. Ob ein mögliches Persönlichkeitsrecht der Wissenschaftler*innen auch in diesen Fällen eine Zuordnung der Forschungsdaten zu einer Person erlaubt, ist umstritten.
9.4.2 Nutzungsrechtseinräumungen im Rahmen von Dienst- und Arbeitsverträgen
Gehört die Schaffung urheberrechtlich geschützter Werke zu den arbeitsvertraglichen Pflichten oder zentralen Aufgaben, werden der*dem Arbeitgeber*in aufgrund des Arbeitsvertrages oder Dienstverhältnisses an diesen sog. „Pflichtwerken“ Nutzungsrechte eingeräumt (§ 43 UrhG). Die folgenden “Zuordnungen” von Forschungsdaten ergibt sich aus dem Interessenausgleich mit der Freiheit der Forschung (Art. 5 Abs. 3 GG):
-
Hochschullehrer*innen stehen im Regelfall alle Verwertungs-, Nutzungs- und Veröffentlichungsrechte an denen von ihnen geschaffenen Werken zu, sofern keine ausdrücklichen vertraglichen Abreden bestehen (z. B. Drittmittelförderung, Geheimhaltungsabreden). § 43 UrhG (sog. "Pflichtwerke") findet hier keine Anwendung.
-
Wissenschaftliche Assistent*innen und Mitarbeiter*innen sind gemäß Art. 5 Abs. 3 GG privilegiert, wenn und soweit die wissenschaftliche Arbeit weisungsfrei erfolgt, erfolgt die Forschung weisungsabhängig ist eine stillschweigende Nutzungsrechtseinräumung an den erzeugten Forschungsdaten anzunehmen
-
Bei Studierenden und externen Promovierenden findet grundsätzlich keine Nutzungsrechteeinräumung an die Hochschule statt, da diese keine Arbeitnehmer*innen sind. Jedoch können abweichende vertragliche Vereinbarungen getroffen werden, z. B. bei Drittmittelprojekten, durch die z. B. der Hochschule Nutzungsrechte eingeräumt werden
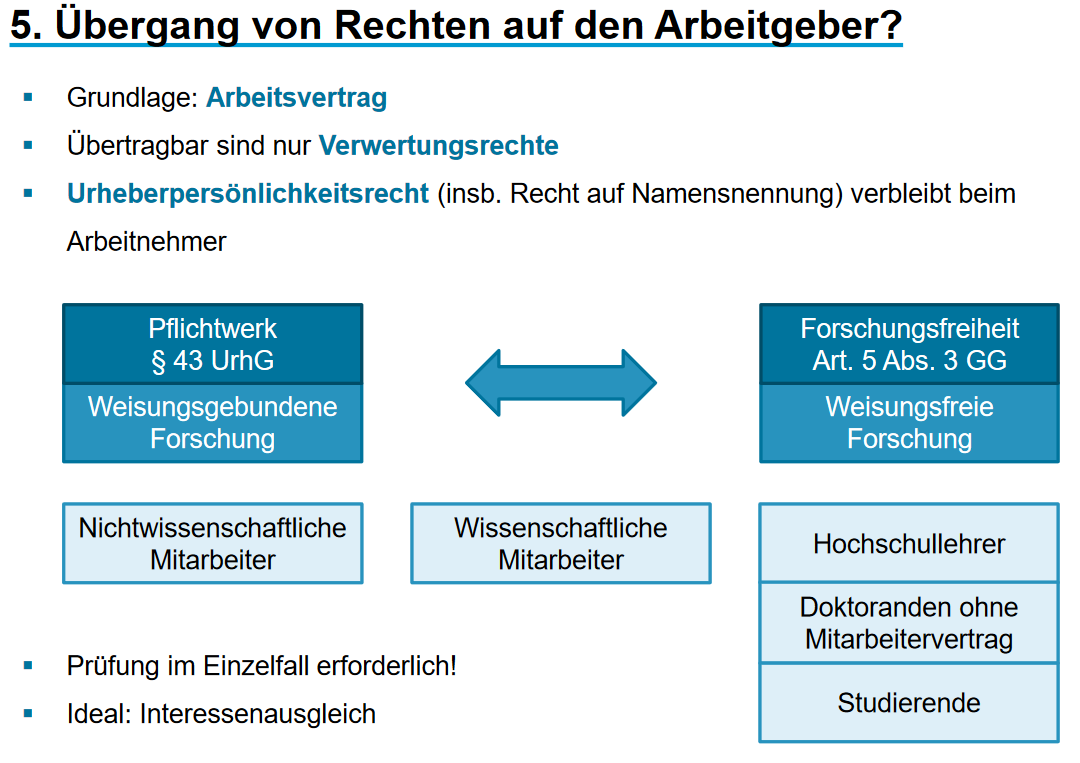 Abb. 9.4: Rechtsinhaberschaft bei Forschungsdaten, Quelle: Wem "gehören" Forschungsdaten, Folie 7Zu beachten ist, dass eine Nutzungsrechtseinräumungen im Rahmen von Dienst- und Arbeitsverträgen ggf. auch stillschweigend erfolgen kann, soweit die Nutzungsrechtseinräumung nicht ausdrücklich im Vertrag geregelt ist. Im Rahmen der (stillschweigenden) Einräumung überlässt die*der Wissenschaftler*in der*dem Arbeitgeber*in auch das Recht zu bestimmen, ob und wie das Werk veröffentlicht wird. Dagegen behält jede*r Wissenschaftler*in ihr*sein Recht auf Namensnennung.
Abb. 9.4: Rechtsinhaberschaft bei Forschungsdaten, Quelle: Wem "gehören" Forschungsdaten, Folie 7Zu beachten ist, dass eine Nutzungsrechtseinräumungen im Rahmen von Dienst- und Arbeitsverträgen ggf. auch stillschweigend erfolgen kann, soweit die Nutzungsrechtseinräumung nicht ausdrücklich im Vertrag geregelt ist. Im Rahmen der (stillschweigenden) Einräumung überlässt die*der Wissenschaftler*in der*dem Arbeitgeber*in auch das Recht zu bestimmen, ob und wie das Werk veröffentlicht wird. Dagegen behält jede*r Wissenschaftler*in ihr*sein Recht auf Namensnennung.9.4.3 Zusammenfassung
Das folgende Video erläutert zusammenfassen das komplexe Zusammenspiel aller bisher erarbeiteten Rechtspositionen für die “Zuordnung” von Forschungsdaten und geht dabei in einigen wenigen ergänzenden Aspekten auch über das bisher ausgeführte hinaus (z. B. Software, Datenträger):
Quelle: „Open Science: Von Daten zu Publikationen“, Peter Brettschneider, Universität Konstanz
-
-
9.5 Veröffentlichung und Lizenzierung von Forschungsdaten
Bevor Daten öffentlich zugänglich gemacht werden können, gilt es, eine Vielzahl rechtlicher Aspekte zu beachten – denn nicht alle Daten können oder sollten veröffentlicht werden. Die wichtigsten rechtlichen Aspekte berücksichtigt die folgende Entscheidungshilfe in Form eines Flussdiagramms. Die Beantwortung der gestellten Fragen führt Sie durch den Entscheidungsprozess bis zu einer Empfehlung:
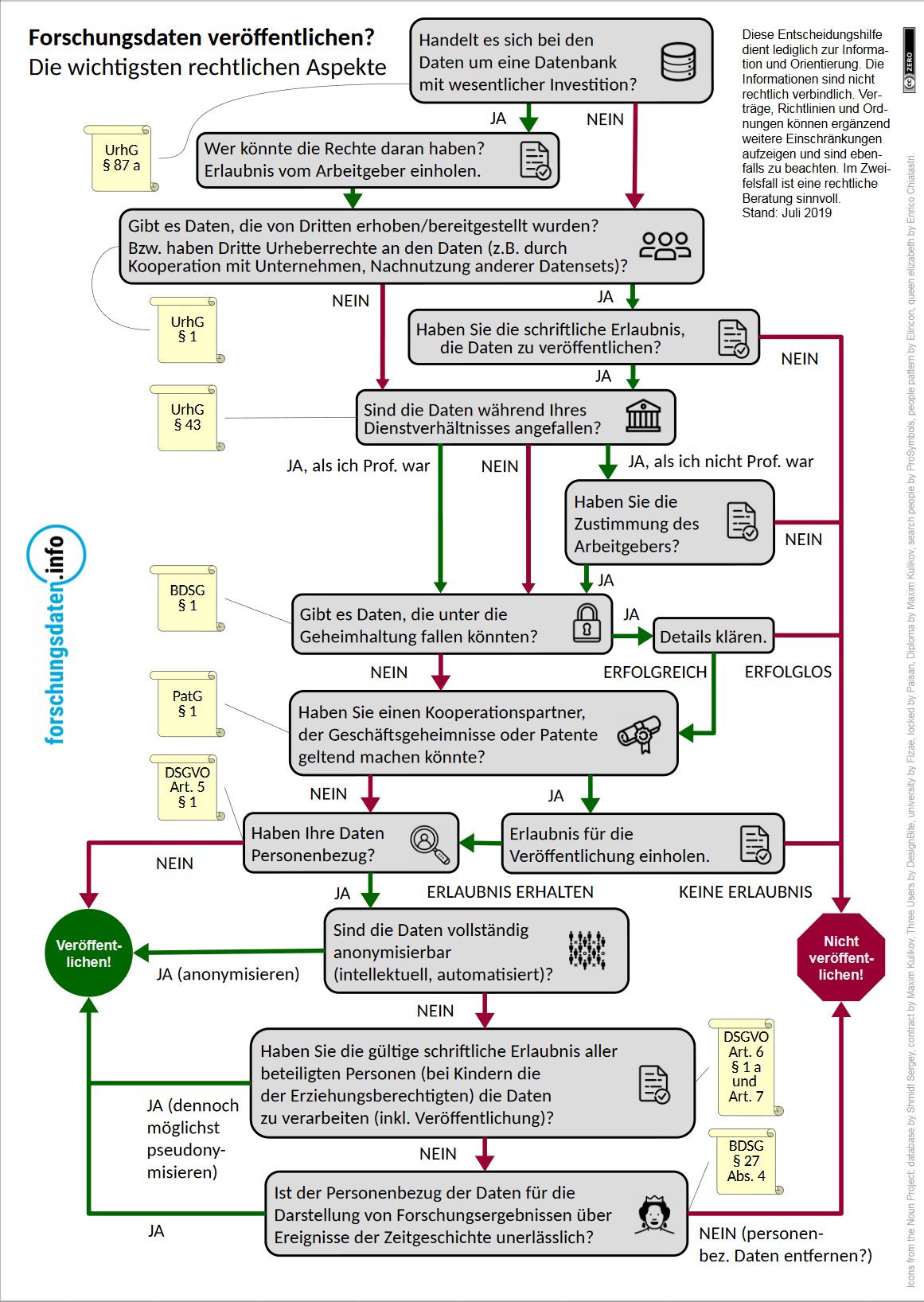 Abb. 9.5: Entscheidungsprozess Datenveröffentlichung, Quelle: forschungsdaten.info, https://zenodo.org/record/3368293
Abb. 9.5: Entscheidungsprozess Datenveröffentlichung, Quelle: forschungsdaten.info, https://zenodo.org/record/3368293
Im Wesentlichen, jedoch nicht ausschließlich, sind vor der Veröffentlichung Fragen des Datenschutzes und des Urheberrechts zu klären. Die entscheidenden Weichenstellungen für die Möglichkeit zur Veröffentlichung von Forschungsdaten in einem Repositorium erfolgen deshalb häufig bereits bei der Erhebung der Daten und der Einholung entsprechender Einwilligungserklärungen.
9.5.1 Was sind geeignete Lizenzierungsmodelle?
Damit Andere Ihre urheberrechtlich geschützten Daten auch wirklich nutzen dürfen, müssen die Bedingungen der Nutzung geregelt sein. Dies geschieht durch die Vergabe einer Lizenz. Existiert keine Lizenz, dürfen urheberrechtlich geschützten Daten nur mit ausdrücklicher Zustimmung der Urheber*innen verwendet werden.
Hingegen sollten nicht urheberrechtlich geschützte Forschungsdaten, deren Nutzung bereits ohne vertragliche Erlaubnis (z. B. Lizenz) zulässig ist, weder eingeschränkt noch mit Bedingungen belegt werden. Aus diesem Grund besteht z. B. unter der CC-BY 4.0-Lizenz auch keine durchsetzbare Verpflichtung zur Attribution (siehe Klausel 8a des Lizenzvertrags).
Häufig werden für das Bereitstellen von Forschungsdaten die Creative Commons Lizenzen verwendet. Neben der Europäischen Kommission im Rahmen von Horizon 2020 empfiehlt auch die DFG die Verwendung dieser Lizenztypen. Bei der Entscheidung für eine konkrete Lizenz gilt die Maßgabe “So offen wie möglich, so restriktiv wie nötig”: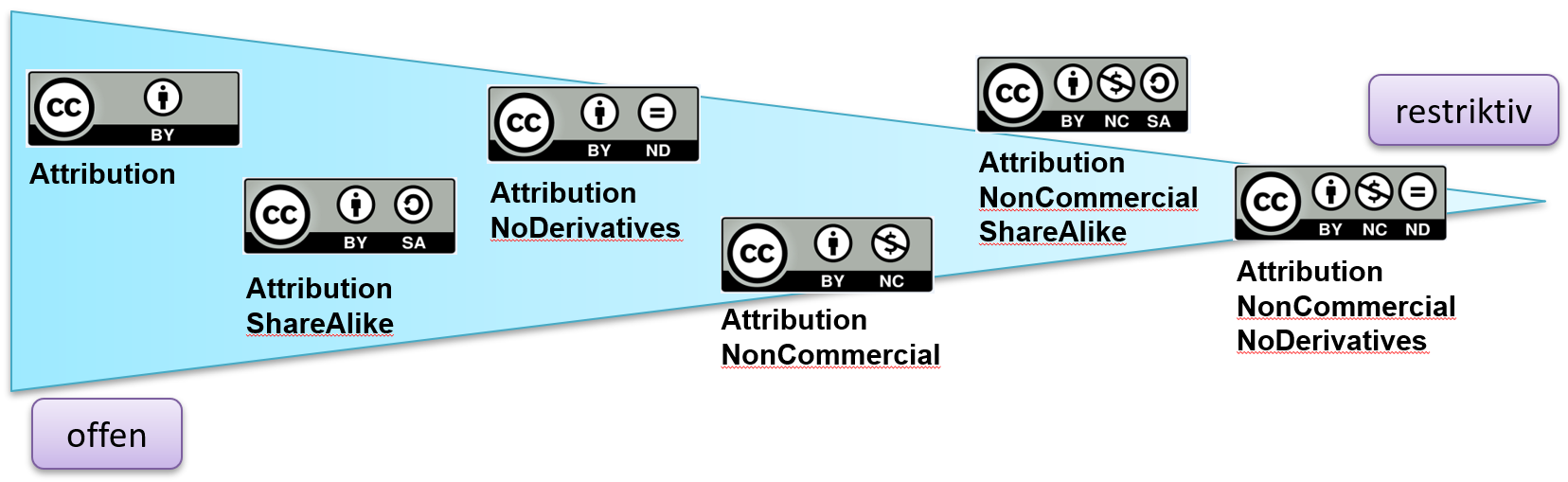 Abb. 9.6: Nutzungsmöglichkeiten von Daten unter verschiedenen Creative Commons-Lizenzen, Quelle: Apel et al. 2017
Abb. 9.6: Nutzungsmöglichkeiten von Daten unter verschiedenen Creative Commons-Lizenzen, Quelle: Apel et al. 2017Die “Kurzfassung des Gutachtens zu den rechtlichen Rahmenbedingungen des Forschungsdatenmanagements” des BMBF geförderte DataJus Projekts an der Technischen Universität, das die rechtlichen Rahmenbedingungen des Forschungsdatenmanagements untersucht hat, spricht sich für die beiden folgenden Lizenzen aus:
Lizenz
Beschreibung
CC0 (Plus)
Die CC0-Lizenz ermöglicht die maximale Freigabe der Daten und erleichtert die Nachnutzung. Ein Recht auf Namensnennung besteht nicht. Insbesondere für Metadaten ist diese Lizenzierung zu empfehlen.
CC‐BY 4.0
Die CC‐BY 4.0-Lizenz ist sinnvoll, wenn eine Namensnennung gewünscht ist. Zugleich wird dem Gebot der Quellenangabe genügt (Sicherung guter wissenschaftlicher Praxis). Die CC-BY 4.0-Lizenz wird daher für die Veröffentlichung von Forschungsdaten empfohlen.
Tab. 9.1: Empfehlenswerte Lizenzen für Forschungsdaten
Die Verwendung weiterer Lizenzbausteine sei nicht zu empfehlen. So schlössen z. B. die Creative Commons (CC) Lizenzen mit dem Attribut „ND“ (z. B. CC-BY-ND) die Weitergabe „abgewandelten“ Materials aus. Somit bliebe die öffentliche Zugänglichmachung einer neuen Datenbank, die aus Teilen anderer Datenbanken geschaffen wurde, ausgeschlossen.
Software benötigt, im Gegensatz zu vielen anderen Forschungsdaten, eine gesonderte Lizenz. Die Verwendung von Creative Commons Lizenzen ist hierfür nicht zu empfehlen. Es stehen aber ebenfalls unterschiedliche Lizenzen zur Verfügung: MIT-Lizenz, GNU General Public License (GPL), GNU Lesser General Public License (LGPL), Apache-Lizenz.
9.5.2 Was kann einer Veröffentlichung entgegenstehen?
Nicht alle Forschungsdaten dürfen oder sollten auch tatsächlich veröffentlicht werden. Bevor Sie ggf. gänzlich auf eine Veröffentlichung verzichten, sollten Sie in jedem Fall prüfen, ob Sie Maßnahmen ergreifen können um eine rechtlich und ethisch unbedenkliche Veröffentlichung doch noch zu ermöglichen. Einen Überblick über mögliche rechtliche Hürden und entsprechende Lösungen gibt folgende Abbildung:
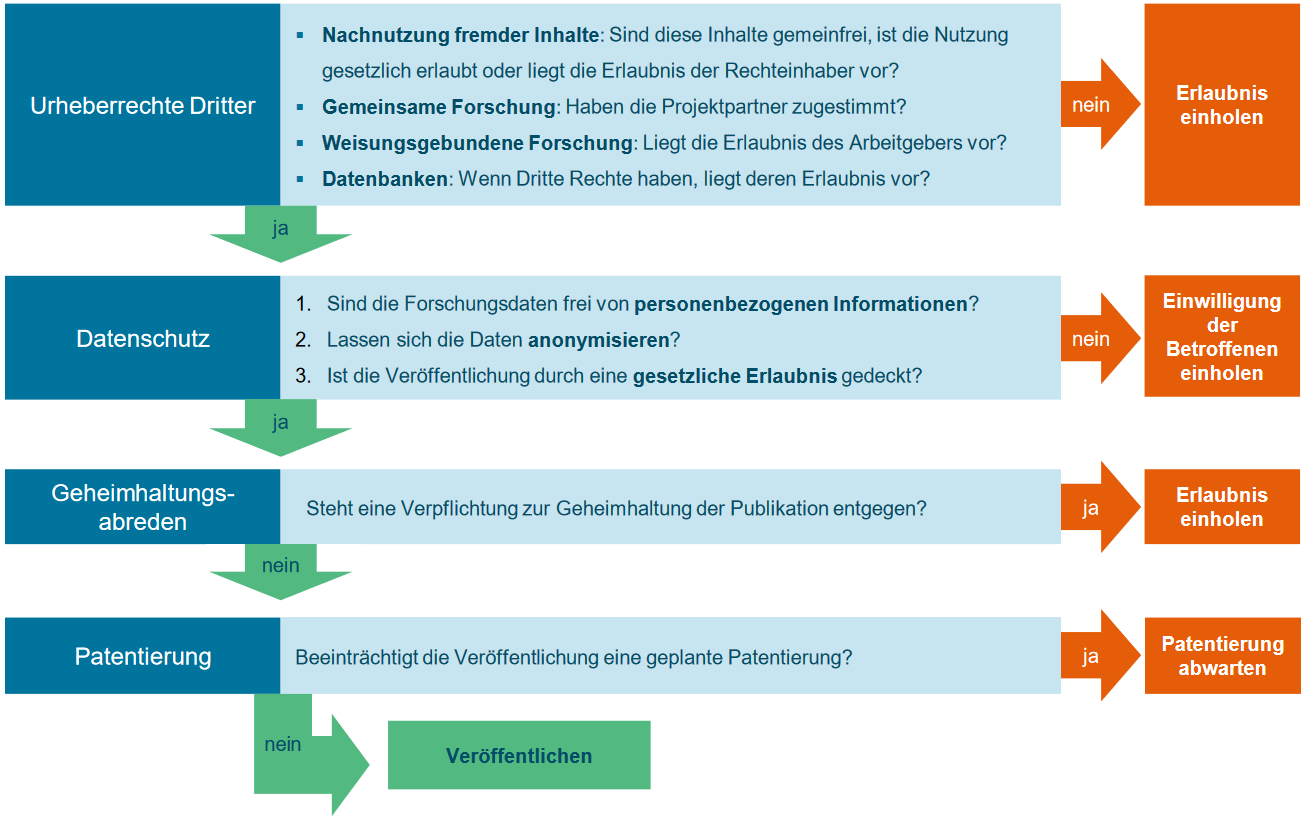
Abb. 9.7: Entscheidungsbaum zur Datenveröffentlichung, Quelle: Böker/Brettschneider (2020)
Darüber hinaus sollten Sie auch forschungsethische Aspekte in Ihre Entscheidung über eine Veröffentlichung Ihrer Forschungsdaten einfließen lassen Die folgenden Punkte sollten Ihnen einige Anhaltspunkte ohne Anspruch auf Vollständigkeit an die Hand geben:
- Können die Daten in einer Weise genutzt werden, die der Gesellschaft schadet?
- Bestehen durch die Veröffentlichung z. B. Risiken für die beforschten Personen (auch wenn diese der Verwendung ihrer Daten zugestimmt haben)?
- Haben beteiligte Arbeitsgruppenmitglieder berechtigte Interessen die Datenveröffentlichung zu unterbinden oder hinauszuzögern (z. B. für die Fertigstellung von Qualifikationsarbeiten)?
9.5.3 Schutz vertraulicher Informationen in Forschungsdatenzentren
Durch die Nutzung von Datenzentren oder auch Archiven ist es möglich, den Zugriff auf vertrauliche und sensible Daten zu beschränken und zugleich eine Datenfreigabe für Forschungs- und Bildungszwecke zu ermöglichen. Die in Datenzentren und Archiven gehaltenen Daten sind im Allgemeinen nicht öffentlich zugänglich. Ihre Verwendung nach der Benutzerregistrierung ist auf bestimmte Zwecke beschränkt. Nutzende unterzeichnen eine Endbenutzer-Lizenz, in der sie sich mit bestimmten Bedingungen einverstanden erklären, z. B. Daten nicht zu kommerziellen Zwecken zu nutzen oder potenziell identifizierbare Personen nicht zu identifizieren. Welche Art von Datenzugriff erlaubt ist, wird vorher mit dem Urheber festgelegt. Darüber hinaus können Datenzentren zusätzliche Zugangsregelungen für vertrauliche Daten verhängen. Quelle: forschungsdaten.info
-
9.6 Zusammenfassung
Das Video “Von Daten zu Publikationen” erläutert abschließend für dieses Kapitel das komplexe Zusammenspiel aller bisher erarbeiteten Rechtspositionen an Forschungsdaten noch einmal im Zusammenhang und geht dabei in einigen wenigen Aspekten auch über das bisher Erlernte hinaus (z. B. Software, Datenträger).

-
-
-
